
AI inference has reached a scale where infrastructure assumptions that once held in the background will no longer do.
The most demanding inference workloads today are not defined by a single prompt and a short response but by long-lived interactions, multi-turn reasoning, and agentic workflows where large volumes of inference history must remain continuously available across multiple turns, multiple sessions, multiple agents, and even across multiple services.
As these workloads grow, the dominant constraint shifts. While GPU compute remains foundational, overall performance increasingly depends on how efficiently inference session history (context) can be stored, retrieved, reused, and shared under sustained load.
This shift is what NVIDIA is addressing today with their announcement of the Inference Context Memory Storage (ICMS) Platform for the NVIDIA Rubin platform. It elevates inference context, largely represented by key-value (KV) cache, into a first-class system resource and provides high-speed access to that context across a pod of 1,152 GPUs.
As the context space grows into the hundreds of thousands or millions of tokens, inference history quickly outgrows any machine’s GPU and CPU memory. The system has to manage much larger working sets, and it must do so predictably, repeatedly, and without stalling execution. This is where KV cache (KV$ in short) management technology such as NVIDIA Dynamo comes in.
NVIDIA Dynamo inference computing framework comes equipped with a hierarchical KV Block Manager that creates a dynamic cache management system that extends from GPU memory to CPU memory and now into a new tier of persistent memory. The NVIDIA Inference Context Memory Storage Platform takes a new ultra-high-performance approach to solving the pressing capacity issue by moving inference context out of GPU and CPU memory and into persistent RDMA-connected NVMe storage so context size is not limited by a cluster’s memory space.
What ultimately determines success is not just that context can be stored, but how the system behaves once that context becomes large, shared, and continuously accessed.
Where traditional approaches fall short
When latency matters, every single operation in the data path will determine the effectiveness of how systems can support inference context data services. Looking across how traditional storage systems are built today, it’s clear that there are a number of inefficiencies that needed to be engineered out of a shared KV$ namespace in order to ensure the absolute lowest time-to-first-token (TTFT).
The Data Path
Since KV retrieval time dominates the inference experience, let’s focus on the time to retrieve data from shared storage. The journey of a piece of data from a shared SSD (or SSDs) to the GPU memory of a client has never been completely optimal. SSD data gets copied into storage controllers, controllers copy data into file servers, file servers copy data into a host’s CPU memory and data is then copied from CPU memory into GPU memory. Here, RDMA helps - where NVMe-over-Fabrics can eliminate a memory copy operation into a controller or file server, and GPUDirect Storage can eliminate the copy from the file server into CPU memory - placing data directly into GPU memory from the file server.
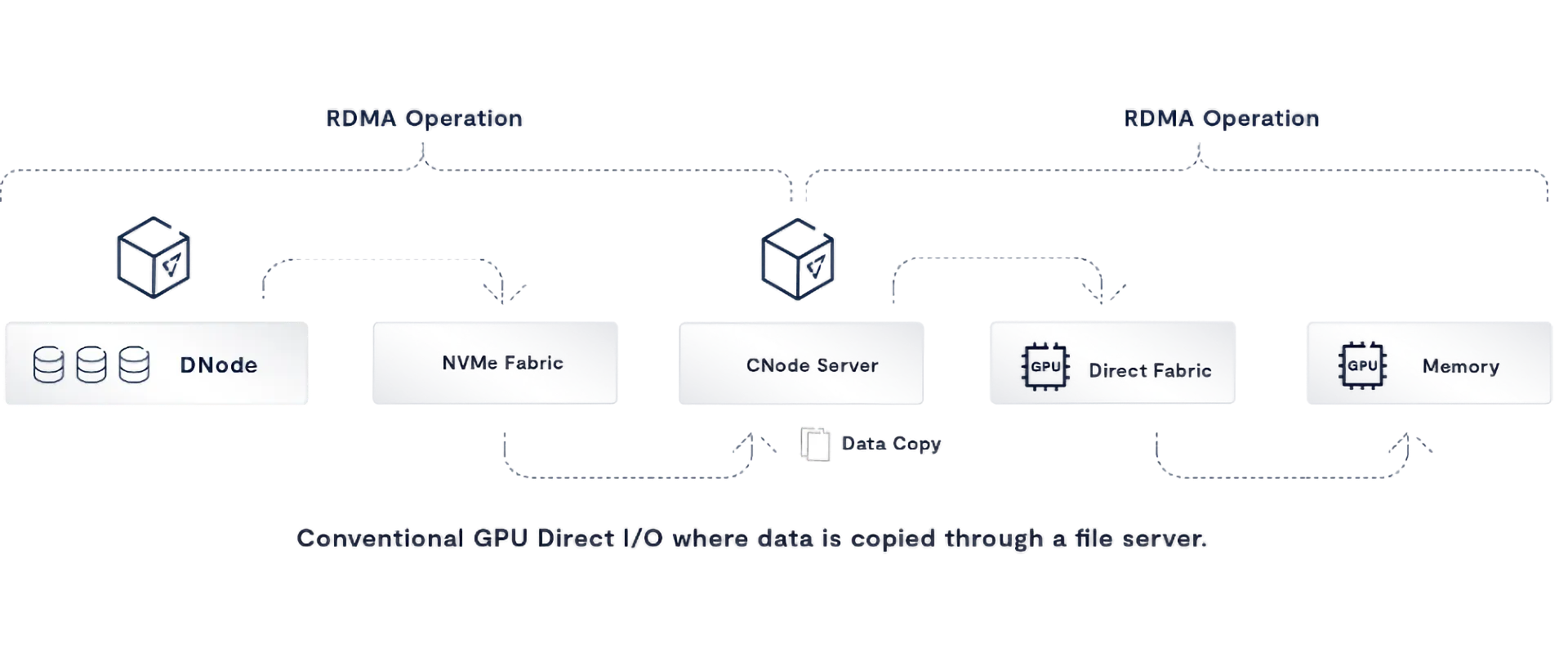
While RDMA has made it possible to build streamlined data paths, there’s still one more copy to eliminate to make the NVIDIA Inference Context Memory Storage Platform architecture maximally performant.
Server Contention
Once we’ve optimized the data path, there’s still the issue of resource contention. Since the dawn of distributed computing, the classic client:server architecture has always dictated that a large number of clients typically compete for a pooled set of shared and limited resources that never assume that all clients are writing to and reading from storage servers at the same time… which is the way that KV Caching operates. To build the most optimized Inference Context Memory Storage Platform architecture, we also need to rethink the classic client:server model to ensure all hosts are concurrently equipped with dedicated and high-performance access to storage server infrastructure.
What VAST changes at the system level
The VAST AI OS delivers the fastest AI data systems we’ve ever built, powered by NVIDIA accelerated computing and AI stack. Through this effort, we can deliver massively-scalable shared KV cache clusters that are not only working to minimize the TTFT, but also minimize the power, space and cost requirements to enable optimzed Inference Context Memory Storage for NVIDIA Rubin clusters.

VAST approaches this problem by rethinking systems architecture altogether.
Server and Data Path Consolidation
The NVIDIA Inference Context Memory Storage Platform embeds data management directly into the GPU server by allowing VAST CNode software to run natively in a node’s BlueField-4 data processing unit (DPU). NVIDIA BlueField DPUs provide the CPU cycles to host all aspects of VAST software - colocating placement decisions, access enforcement, and fast-path metadata resolution directly onto the GPU host and eliminating a whole fleet of x86 servers. Now, I/O processing happens close to execution, where inference actually runs.
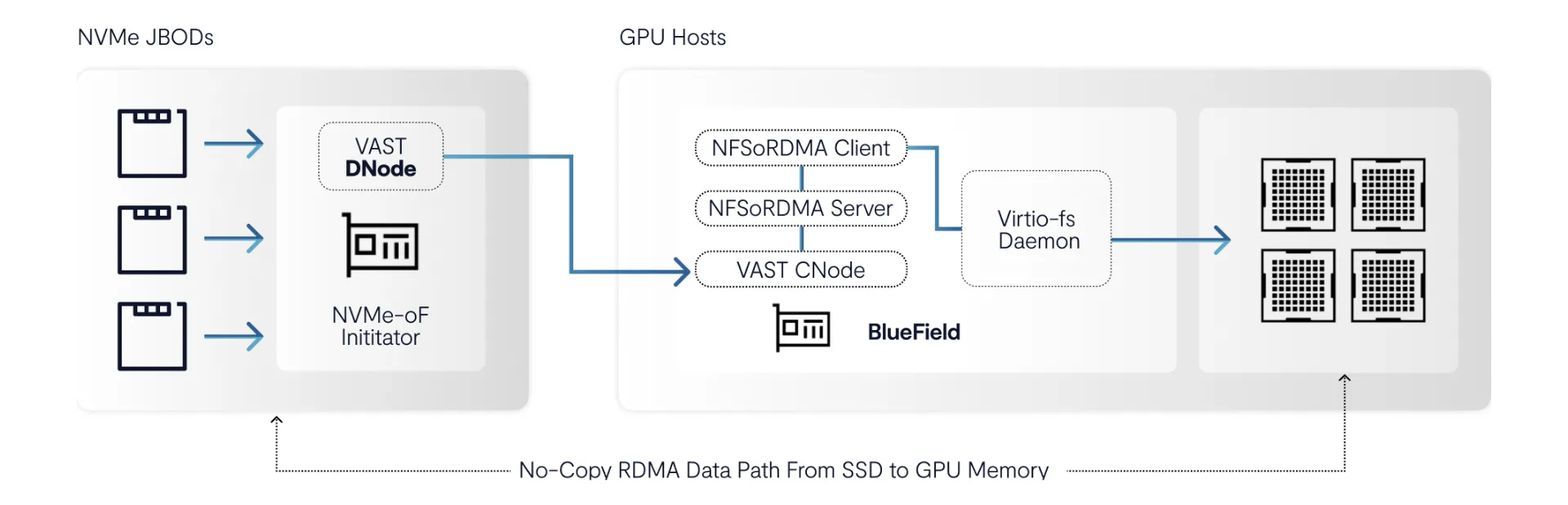
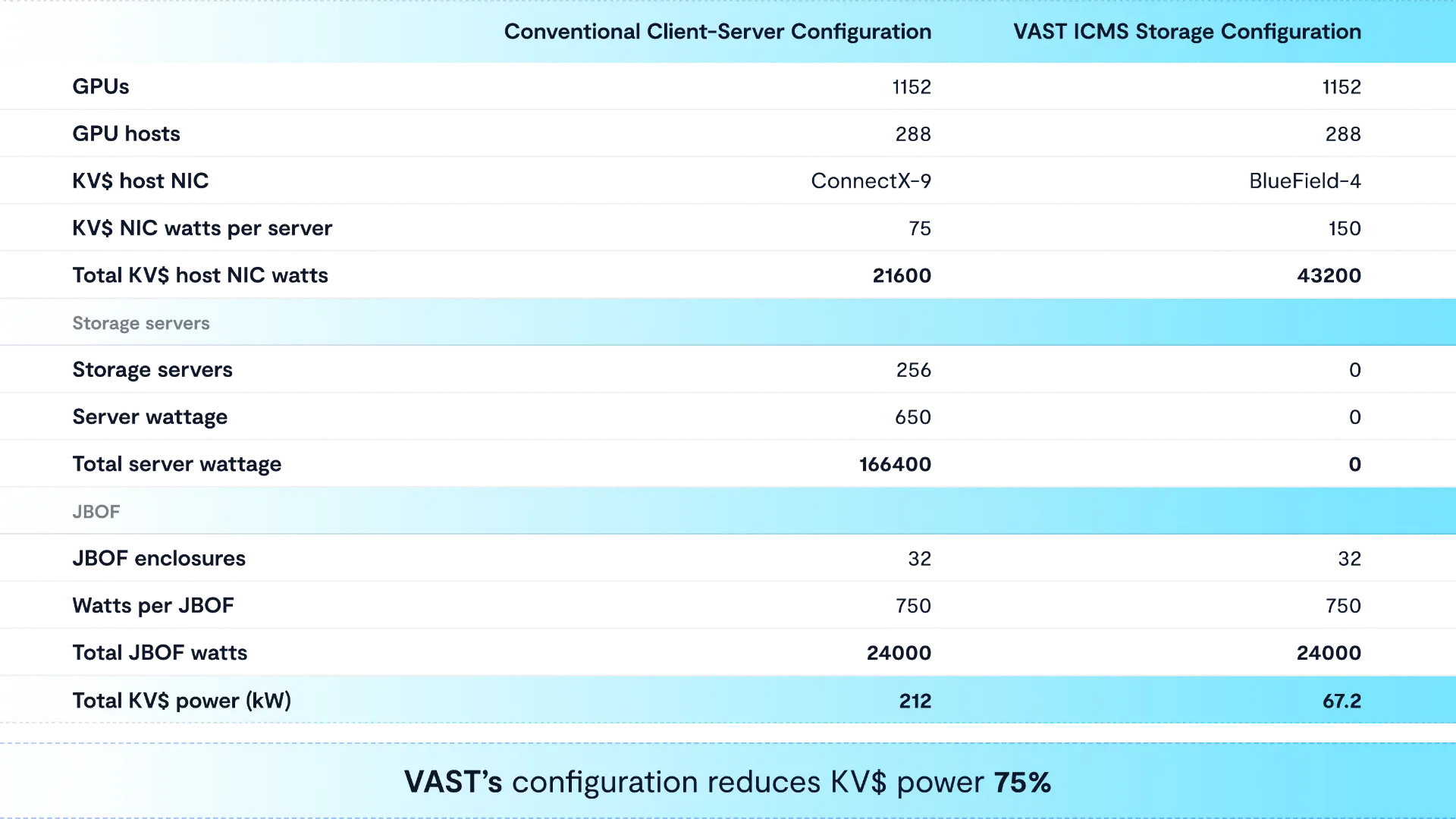
The result is a solution that not only saves big money on x86 HW costs, it also saves power.
Second, by eliminating the x86 server layer, VAST RDMA clients can implement zero-copy I/O operations directly from GPU memory (using GPUDirect Storage) all the way to the NVMe SSDs that KV data is stored on and retrieved from. By eliminating a copy operation, we can further reduce time-to-first token.
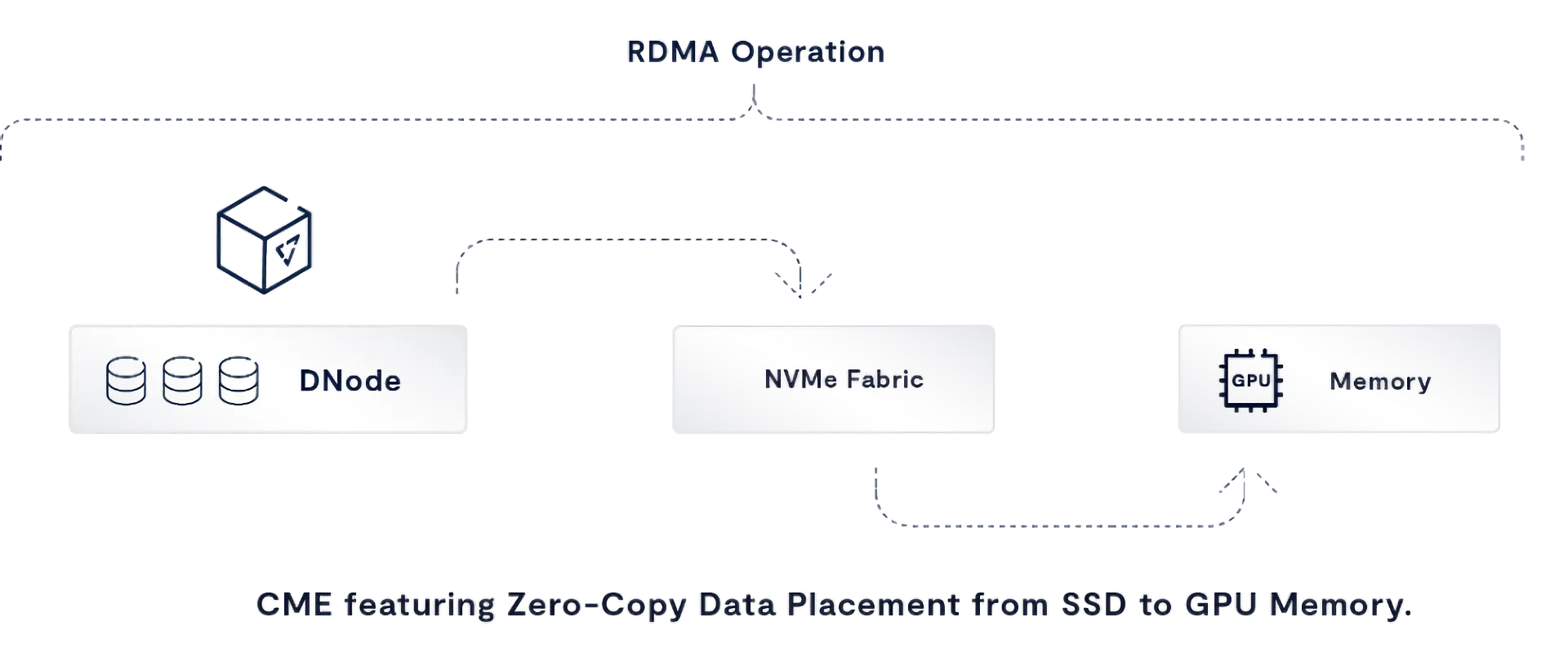
How is it possible to embed servers into GPU hosts without adding complication? This is all possible thanks to VAST’s revolutionary DASE architecture. DASE enables each CNode server container to operate completely in parallel, imposing zero east-west traffic within a multi-server storage environment. Since none of the servers are exclusive owners of a partition of a file systems storage device (as is the case with conventional enterprise NAS systems and parallel file systems), then each host can have its own dedicated file server without getting bothered by any other host-resident file server in a large GPU cluster.
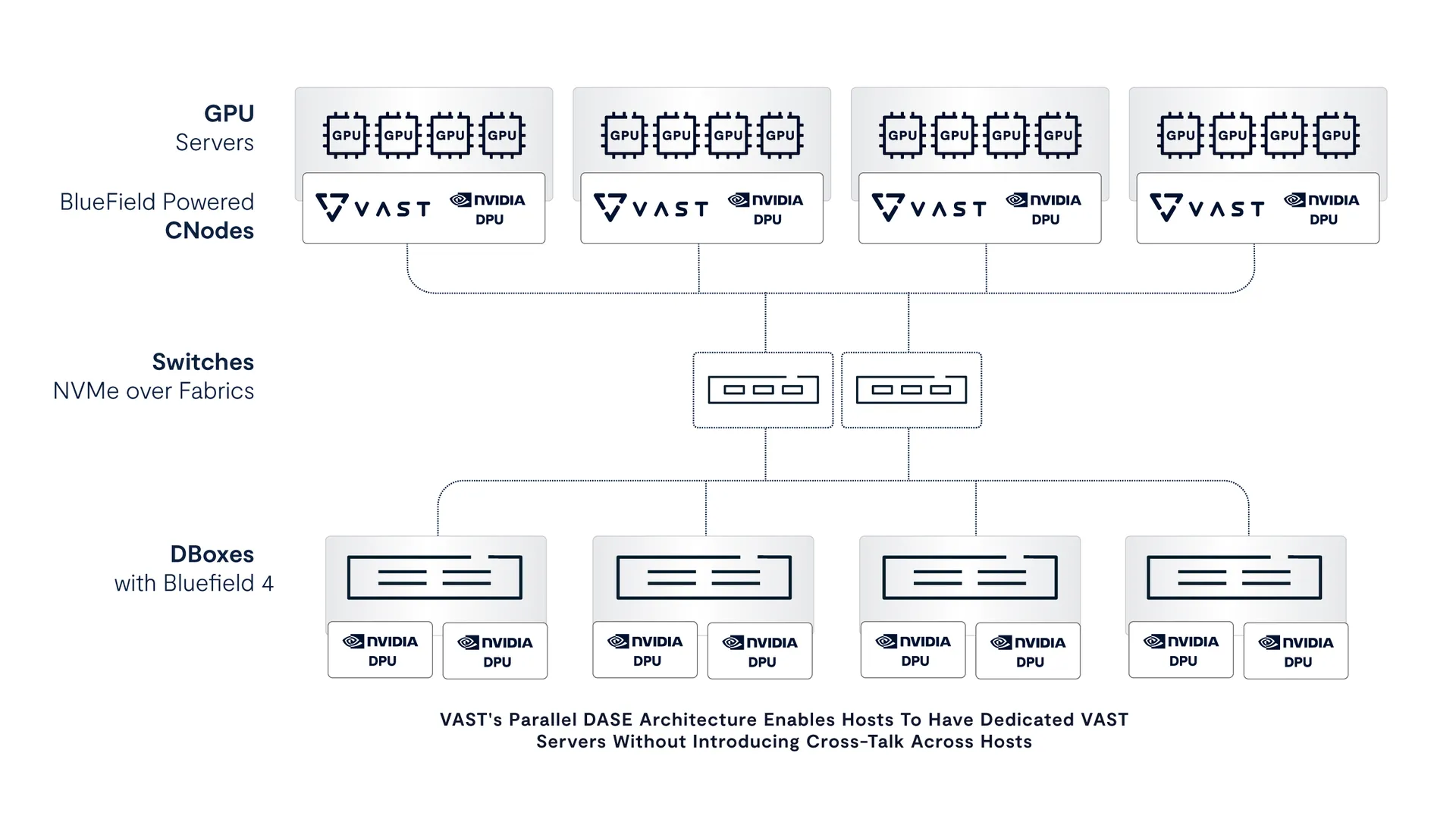
VAST’s parallel DASE architecture executes control logic on BlueField-4 DPUs, eliminating east-west coordination while allowing each host to access all SSDs in parallel. Each DPU sees the full storage namespace directly, delivering dedicated bandwidth per host without cross-talk as inference concurrency scales.
Performance Without Data Services Compromise
Since KV data is easily reproducible, we can provide AI labs the tools needed to both optimize for performance while also making it possible to enable a variety of tools for data management. As AI Inference moves out of its exploratory phase into serious application, some AI labs must build services to meet the requirements of heavily regulated industries. With VAST - they don’t need to choose only for maximum performance and can enable a set of optional data services that help them deliver safe and reproducible AI. We can envision a future collaboration with the NVIDIA Dynamo team where Dynamo APIs direct Inference Context Memory Storage systems to handle different data sets differently as they talk to shared services.

Since VAST’s parallel DASE architecture can add additional CNodes out of band, the result is inference history that remains accessible and globally manageable as inference KV$ concurrency increases, while providing a set of tools to provide background services that do not reintroduce the data management overhead the Inference Context Memory Storage Platform is designed to eliminate.
How BlueField-4 enables this shift
The Inference Context Memory Storage Platform architecture aligns directly with the NVIDIA BlueField‑4 DPU's operation.
DPUs create the opportunity for new storage service deployment paradigms. By adding accelerated processing cores directly onto a network adapter, this advanced data processor serves as the enforcement point for placement, access, and validation directly in the data path. By executing these functions on BlueField-4 at line rate, the host CPU is removed from the critical path as DPUs can now talk directly to NVMe devices in storage enclosures over a shared NVMe-oF fabric. Fewer components participate in each access, fewer transitions are required, and system behavior becomes more predictable under load.
How NVIDIA Spectrum-X enables this shift
NVIDIA Spectrum‑X Ethernet fabric plays a critical role by delivering low-latency, high-bandwidth transport with congestion control and performance isolation for large AI fabrics. The platform is designed to operate on the Spectrum-X Ethernet fabric as part of the broader Dynamo inference orchestration framework and enable predictable KV$ service under sustained cluster-wide load.
Flexibility across deployment models
This behavior is not tied to a single hardware form factor.
While early deployments may showcase dense and fault-tolerant NVMe enclosures for efficiency and footprint, the NVIDIA Inference Context Memory Storage Platform + VAST architectural principles extend naturally to other configurations built from commodity storage servers. Because inference history is shared across the system and access is enforced close to the GPU, the loss of any individual server does not trigger a system-wide context rebuild in the case where customers choose to disable erasure encoding. Inference continues using the remaining distributed history, avoiding the large-scale recreation events that traditionally follow node failures.
Functional outcomes that matter
The impact of this architectural shift is straightforward.
Inference history becomes accessible as a shared system resource without forcing every access through a centralized and limited storage server processing tier. GPU utilization improves because access decisions and context retrieval happen closer to execution. Concurrency scales because each GPU machine has its own dedicated and parallel data processing services. Power efficiency and infrastructure footprint improve because the whole solution has been fully optimized for end-to-end KV cache serving.
These outcomes align directly with the NVIDIA Inference Context Memory Storage Platform's focus on sustained throughput and power efficiency at scale.
A leap in coherent inference
The platform defines context history as a first-class system memory resource. NVIDIA BlueField-4 provides an efficient storage controller and the enforcement point for placement, access, and isolation at the boundary where inference runs. Spectrum-X Ethernet provides predictable transport. Dynamo provides orchestration.
VAST delivers the software core that allows these components to operate as a unified and coherent system, keeping inference history accessible, governable, and efficient as context sizes, concurrency and regulatory requirements continue to grow.
Want to see how this all works in practice? Join VAST and NVIDIA for the “Breaking the Inference Bottleneck: How NVIDIA KV Cache and VAST Unify Performance, Scale, and Efficiency for the AI Era” webinar to learn how their joint architecture dramatically accelerates AI inference — cutting time-to-first-token, boosting throughput, and reducing GPU cost at scale.
Experience VAST’s industry-leading approach to AI and data infrastructure at VAST Forward, our inaugural user conference, February 24–26, 2026 in Salt Lake City, Utah. Engage with VAST leadership, customers, and partners through deep technical sessions, hands-on labs, and certification programs. Register here to join.


