
When organizations consider utilizing a multi-protocol solution, there are multiple challenges they must address. Issues surrounding the handling of user identities and permissions must be considered and addressed with any solution, but how each of those aspects applies and needs to be addressed will depend greatly upon not only the use case but the process flow of how data is created, managed, and used.
Data Process Flows
The first thing to consider really is the process flow of your data. How is the data created and by what methods and via what protocols and how then it is used? Data creation from a set of microscopes via SMB using a single service account is much different than home directories of users or the output directories of graphic render farms. Additionally, workloads that are read-only or read-mostly from a single protocol are much different than ones that may be read and written from multiple protocols.
Handling of permissions upon file creation and later modification of permissions, as well as the granularity or flexibility of permissions, vary greatly between protocols. Let’s look at a few examples.
Sorting Permissions Between NFS, SMB, and S3
In the traditional world of POSIX and NFSv3 permissions are governed strictly by mode bits that grant read, write, and execute permissions to the owner of the file or directory, the members of a particular group, or everyone. The notion of what each of these individual mode bits do and grant depend upon if the object is a file or a directory.
For instance, if the “x” (or execute) bit is set on a file, it would allow the grantee to execute or run the file. But if this is set on a directory, the bit would allow the user to traverse the directory via a “cd” command to possibly access the files or subdirectories contained within.
File creation with these traditional POSIX mode bits is typically governed by a UMASK that determines the initial mode bits by masking certain ones out. This will default to 022 on many UNIX or Linux systems.
For Windows and SMB, file creation and permissioning is handled much differently. Rather than relying on basic permissions (Owner, Group, and Everyone) as POSIX does, NTFS-style permissions utilize inheritance and access control lists (ACLs). Permissions are also much more granular. For example, instead of a singular “write” permission governing a directory to control file creation and deletion, there are permissions for both File Delete and File Create that are handled separately.
Additionally, Windows and SMB have no concept of a UMASK as seen in POSIX and NFS. Instead, initial file permissions are determined by inheritance rules as defined from individual ACL entries. For instance, a directory may have an individual ACE that states that files created in that directory are to be granted read-write permissions to the “research” group and another entry may state that for the same file, read-only rights on new files will be granted to user “frank.”
NFSv4 while at first glance might seem similar to NFSv3 adds the ability to set a far more robust set of ACLs than were available to NFSv3. These NFSv4 ACLs are similar in granularity to those available to SMB and NTFS and in many cases directly translate between the two. In terms of file creation, like NFSv3, NFSv4 does honor UMASK but this only applies to those ACLs affecting the trivial Owner, Group, and Everyone permissions.
For S3, the permissioning model is completely different. S3 does away with the traditional file and directory model and is object-object based. Rather than a tree model of directories and subdirectories, S3 places objects into buckets without any real hierarchy. S3 also doesn’t have a concept of editing and modifying the contents of an object in place, rather an entirely new object is uploaded. S3 does have the concept of an ACL for objects and buckets to allow or deny access, but it also introduces policies for buckets and users to control which actions are allowed or denied.
Who Are You?
The identification of users between different protocols, or user-mapping, is also critical. For Windows and SMB, individual users and groups are identified via a SID (aka Security Identifier). For POSIX and NFSv3, users and groups are identified by numeric UIDs and GIDs on the wire and on disk. For NFSv4, either numeric UIDs and GIDs could be used or a UPN (User Principal Name). S3 utilizes public and private keys to identify users. Mapping between each of these types of identifiers is challenging as the required information may or may not be contained within a single object within a single naming provider. While this can be accomplished via static naming maps, those are not flexible enough or dynamic enough to scale to large environments. Flexibility in using a variety of different naming services (NIS, Active Directory, LDAP, etc.) is required.
Ultimately, the requirement is that for any object, be it a file or directory, a user should be able to access their data with the same permissions regardless of the protocols being used.
Summarizing the Issues
To summarize the issues outlined above there are several issues that need to be addressed in order to be successful with multi-protocol solutions.
Differences in permission granularity
Differences in initial file creation behavior
User identifiers and mapping between multiple naming service providers
Maintaining consistent access rights for users, regardless of protocol
Controlling permission changes
In order to handle situations and protocols where permission granularity differs, as well as the ability to be able to handle additional protocols and permission schemes going forward, the options are to either maintain separate permission lists per-protocol or to have a single permission set. Since the desire is to maintain consistent access rights for users, regardless of protocol, it makes little sense to have multiple per-protocol permission sets, and as such a single permission set is needed.
Abstraction and Extension
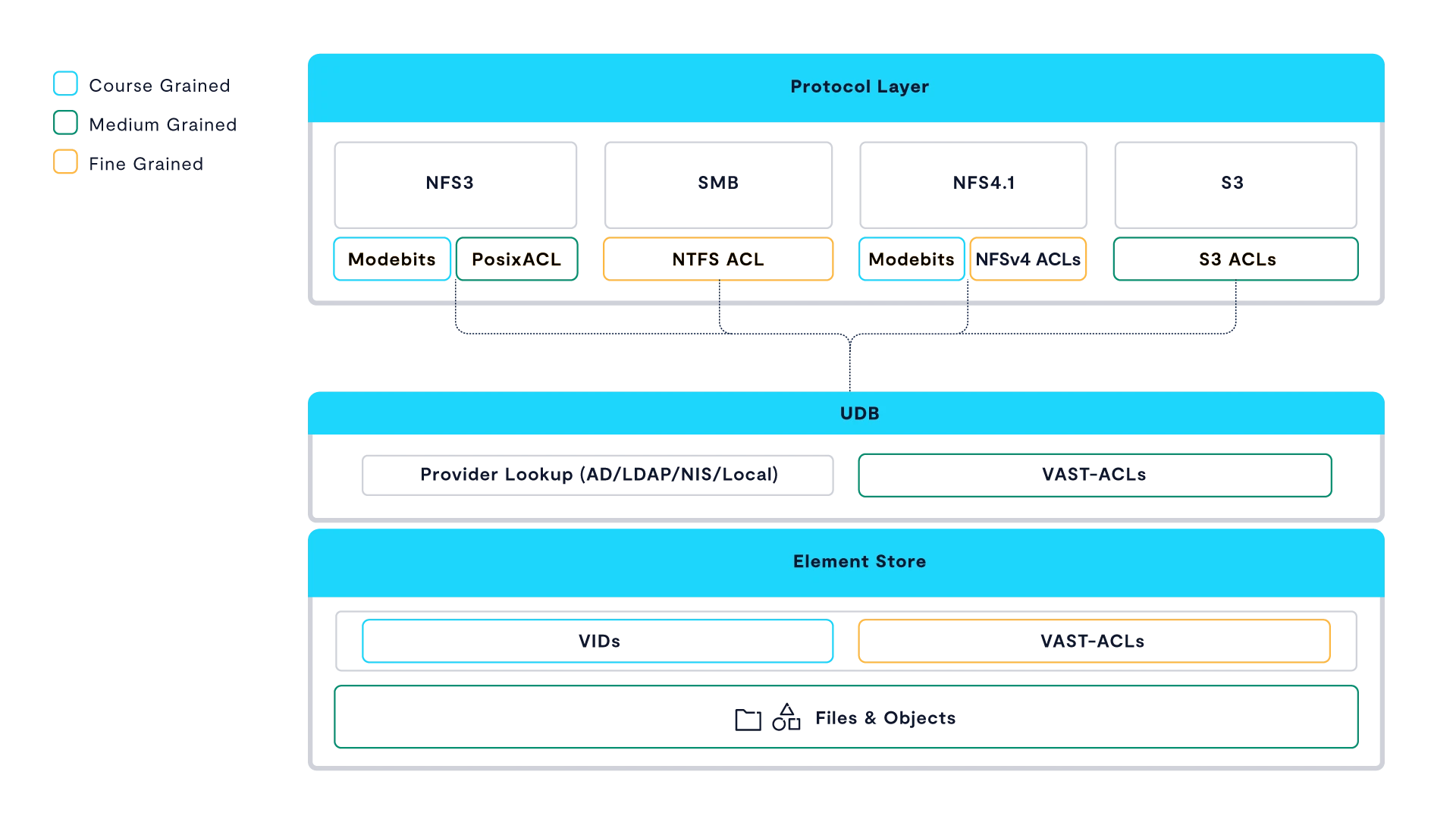
Within VAST, permissions are stored as VAST Permissions rather than their native format. VAST Permissions are a superset of all supported protocols with defined mappings and representations for conversions to and from each protocol.
While individual protocols may be less granular than the VAST permissions, certain operations can be allowed or denied based on the VAST permissions, even if they can’t be readily displayed on protocol that is currently being used. Additionally, changes made to permissions via one protocol are immediately effective and enforced in other protocols since there is ultimately only a single permission set.
Examples of a “read” permission across different protocols and translation to VAST Permission:
POSIX mode bits | NFSv4 ACE | S3 | Windows / SMB | VAST permission representation |
|---|---|---|---|---|
dr-- | r (list-directory) | bucket READ | FILE_LIST_DIRECTORY | DIR_READ |
-r-- | t (read-attributes) | object READ | FILE_READ_ATTRIBUTES | FILE_READ_ATTR |
-r-- | r (read-data) | object READ | FILE_READ_DATA | FILE_READ |
-r-- | N/A | object READ | FILE_READ_EA | FILE_READ_EXT_ATTR |
Users and Groups are handled in a similar fashion. Many multi-protocol solutions are based on a single native file system. Users and groups are then translated between them and stored in that native format. This requires constant translations and various static lookup tables or other gymnastics when additional protocols are added.
VAST is different. Rather than store user and group ownership directly with the file, these are abstracted to VAST IDs. As a new user or identifier is encountered, a new VAST ID is created. Users and group membership is then identified across protocols by consulting each of the defined Providers (LDAP, Active Directory, NIS, or Locally-Defined) known to the cluster.
While, for instance, POSIX Attributes may be stored with a User object within Active Directory to identify the same User between SMB and NFS, so long as there is a common value for an identifier between Providers (ie. cn in OpenLDAP and sAMAccountName ActiveDirectory) different, dis-jointed providers can be used for this mapping.
The mappings for a User between providers is cached so as to not overwhelm the Providers with constant lookup requests, and refreshed periodically. In order to conserve resources, if a User is idle for a period of time this association may be freed from memory, but will be looked up again when the User again becomes active. If a new Provider is added or removed from the system, the identifiers for a User between each of these Providers and protocols can be immediately updated to provide access via that protocol.
Taking this abstracted approach provides a few distinct advantages:
Administrators can add or update identifiers (eg: uidNumbers) for a given user without the need to re-write permissions to any previously written data.
New attributes (such as S3 access Keys) can be added to a user’s profile at any point, and said attributes and/or authentication credentials will be effective for authorizing access to previously written data.
When (not if) new types of protocols and related identifiers emerge as a standard in the future, they can be incorporated into the authorization flow to allow seamless access to all data.
Historically, such an abstraction and internal mapping database was challenging to develop and deploy at scale because of the need for this data to reside on low latency, highly available, and consistent storage. On VAST, the userdatabase takes full advantage of our unique DASE architecture and use of StorageClassMemory.
Introducing VAST Security Flavors
The topic of permission control is also to be considered. When a “chmod g-w” is run from a NFSv3 client, how should that be interpreted? If in a NFSv3 only environment, this simply means remove write access to the group-owner of the file or directory. However, what if this is a joint NFSv3 and SMB environment? Does this mean remove write permissions from all groups or just one group? Is this a case where it should be even allowed?
VAST handles these controls with Security Flavors. A Security Flavor quite simply is defining the behavior of the View when it comes to handling permissions. Security Flavors define which protocols can be used to set or change permissions, the order in which ACE’s (Access Control Entries) are processed, and how initial permissions on files are defined.
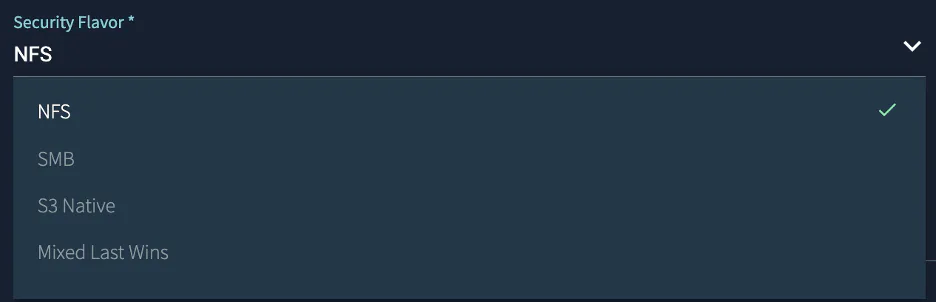
VAST currently defines four different Security Flavors. NFS, SMB, Mixed-Last-Wins, and S3 Native. Each of the Flavors, while able to support multiple protocols, will behave differently and have different rules.
For the NFS Security Flavor, behavior follows NFSv3 rules. There is an option for NFSv3 POSIX ACLs, but these are not required. There is no support for NFSv4 ACLs or NTFS ACLs. Files are created according to the user’s UMASK over NFSv3 and NFSv4.
With the NFS Security Flavor, when it comes to file and directory creation via SMB and S3, the initial POSIX mode bits are explicitly defined by policy. Permission modifications via chmod, chown, chgrp, setfacl are allowed for NFSv3 or NFSv4 but denied when permission modification attempts are made via SMB or S3. Most programs do not attempt to set or change permissions via SMB so an error is returned as permission denied for all attempts via SMB to modify permissions.
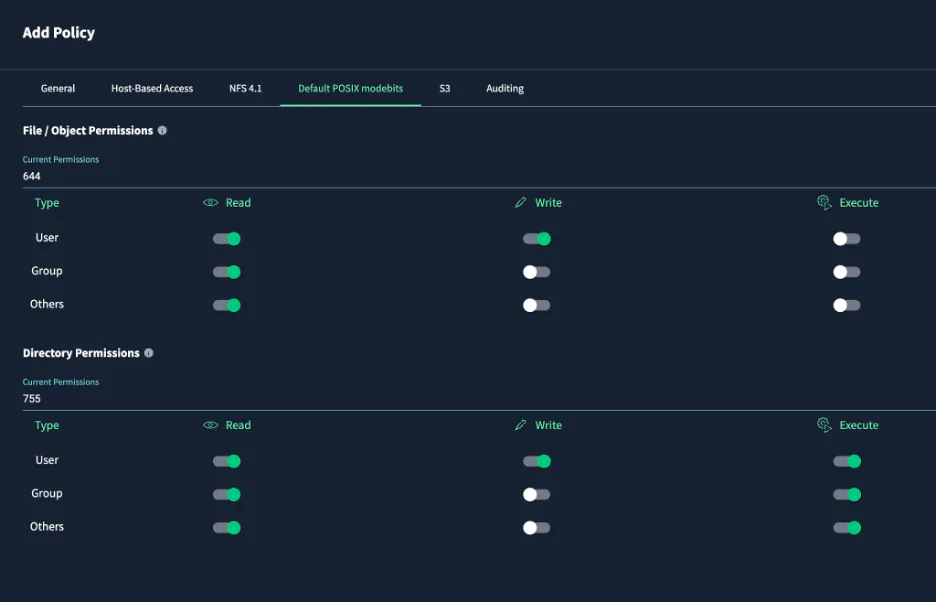
For the SMB Security Flavor, ACLs are set and defined via normal Windows tools. Full NTFS ACLs are able to be seen and set. If files are created via NFS, the UMASK is ignored completely and instead files will inherit permissions (including ACLs) as defined in the directory in which they are created, just as file creation would be handled under SMB. Permission changes are not allowed via NFS. However, unlike SMB, it’s very common for many UNIX programs to do a file create followed by a permission modification and since this may cause unnecessary errors, any attempts will instead silently fail.
The Mixed-Last-Wins Security Flavor exposes the full ACL set to both NFSv4 and SMB clients and allows for either protocol to set or change permissions. NFSv4 is fully ACL aware and per the NFSv4 RFC, file creation when ACLs exist will inherit those ACLs. With NFSv4, the nfs4_setfacl command can be used to change and modify ACLs as can standard Windows tools over SMB.
The S3 Native Security Flavor allows for the use of S3 Identity Policies to control access and the ability to set and change ACLs according to S3 rules. Like the SMB Security Flavor, attempts to modify permissions via NFS would silently fail.
Putting It All Together
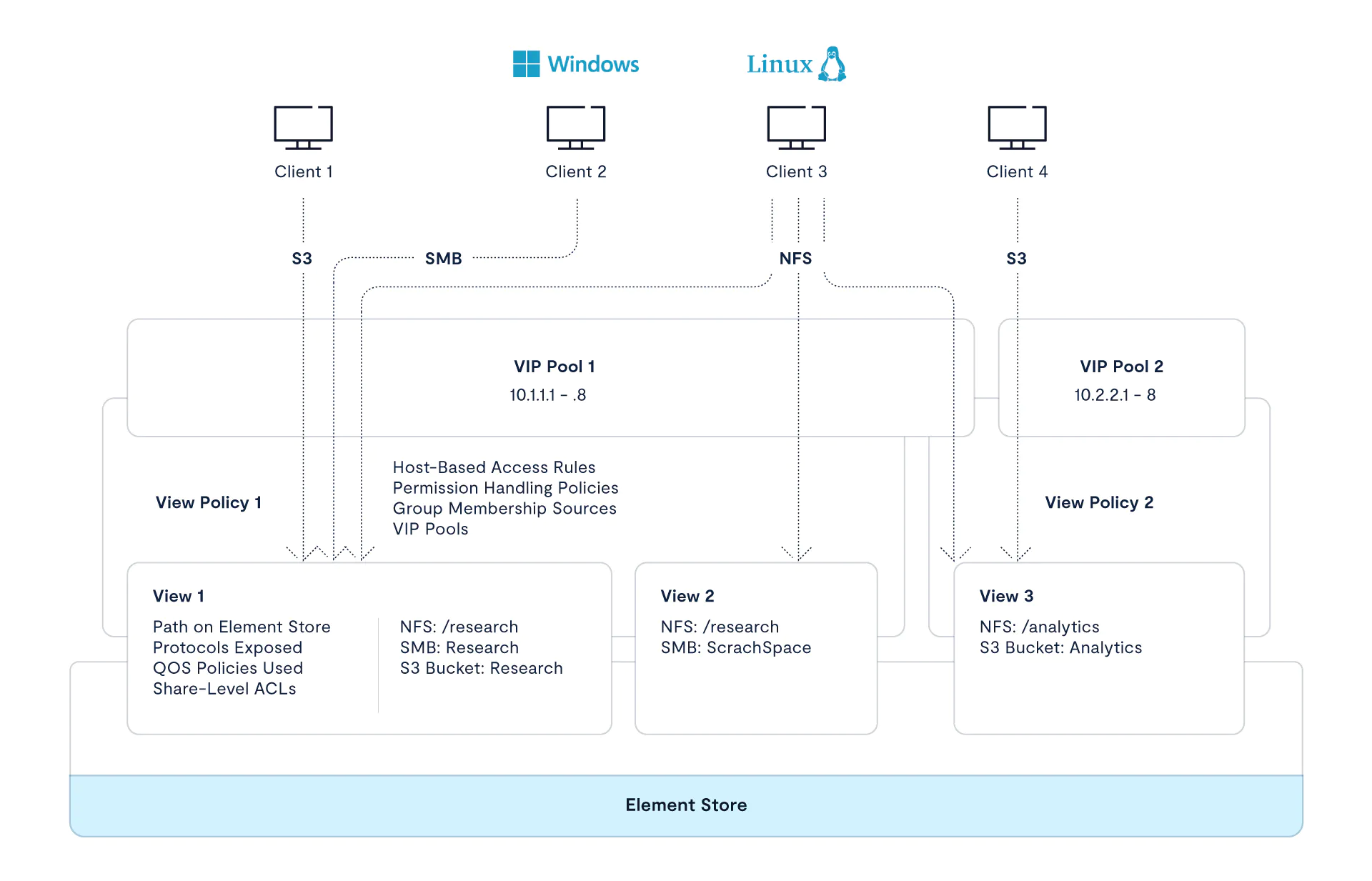
VAST refers to a share as a View. This is because it is effectively a view into a path in the Element Store where the data resides.
Each View may be wholly unique in its use case, or multiple Views may be similar in terms of how the data within them is to be accessed and used.
VAST uses a View Policy to define the behavior of one or more Views. The Security Flavor to be used, default POSIX mode bits, host-based access rules, and additional security settings such as kerberos authentication are defined within a View Policy. When a new View is created, a View Policy to use is selected. By utilizing View Policies, one can easily create new views with similar uses as well as make modifications to multiple Views at once.
In Conclusion
Multi-Protocol has many uses and applications, but as we can see there are caveats and considerations that have to be taken into account in order to implement them properly. There truly is no “one size fits all” approach to all use cases and as such care must be taken to outline the intended flow in both the creation and accessing of data. This is especially the case surrounding setting and modifications of permissions.
By abstracting protocol-native permissions into a super-set of VAST permissions, consistent access across different protocols can be maintained. Additionally, VAST Security Flavors allow for flexibility and control of behaviors in managing the different methods and granularity of permissions between protocols. This flexibility is key in meeting the business requirements of our customers and truly makes VAST a single platform for all your data.


