
CPUs have been a data-processing workhorse for decades, but a rise in demanding AI workloads - such as multi-agent systems, video-reasoning, and high-volume RAG - is driving demand for GPU-based acceleration. Defined by real-time, high throughput, complex queries, and extremely low latency, these types of jobs are blowing past the ability for CPUs alone to keep up.
VAST and NVIDIA are collaborating on AI systems capable of delivering these capabilities within mainstream enterprise environments. Two weeks ago, we unveiled the VAST CNode-X server, which combines the VAST AI OS with NVIDIA data-processing libraries and onboard NVIDIA PRO™ 6000 Blackwell Server Edition GPUs. The CNode-X solution leverages the NVIDIA AI Data Platform reference design to accelerate workloads like data vectorization, vector search, and inference. VAST also highlighted a series of benchmarks that demonstrate the scale and performance of its native vector database, achieving very high throughput, performance, and recall across a sample size of 50 billion vectors.
For background:
Vector storage and processing on VAST (referred to here as the VAST vector database) are capabilities of the broader VAST DataBase, which also supports transactions and analytics on structured data. Vector embeddings are stored alongside structured data and metadata in the same tables, and natively integrated with unstructured data in the VAST DataStore. This enables hybrid queries across modalities, without orchestration layers or external indexes.
NVIDIA cuVS is an open-source GPU-accelerated library for vector search and data clustering, that enables faster vector searches and index builds. It supports scalable unstructured data-processing workloads like large-scale indexing, and powers low-latency and massive-throughput vector search. NVIDIA cuVS is the default GPU backend of an ecosystem of vector search libraries and vector databases.
NVIDIA cuDF open source library, accelerates popular data engines like Apache Spark, pandas, and Polars on NVIDIA AI infrastructure. Built on Apache Arrow, it utilizes GPU parallelism and memory bandwidth to accelerate data processing and analytics workflows. cuDF is the data-processing foundation of the Sirius GPU-accelerated database project.
Now, we’re diving deeper to show what it looks like when we combine these two efforts by running some key data-processing benchmarks on GPU-based systems.
Faster ingestion, indexing, and reading for real-time RAG
A major inhibitor of real-time AI pipelines is simply how long it takes to execute any given step using CPU-based systems. GPU acceleration helps resolve these issues by offloading certain compute-intensive tasks to GPUs, and thus freeing up CPUs to execute the tasks to which they’re better suited.
Ingesting and indexing many terabytes or petabytes of unstructured data, for example, can take days or weeks, and that process is repeated whenever an upstream component (such as the embedding model) is updated. This is untenable for organizations generating large data volumes every day — in the form of documents, videos, agentic interactions, or event logs — and needing immediate access to that fresh data.
On the flipside, faster ingestion and indexing helps users test new ideas quickly and bring them to market faster. Let’s say, for example, that a user has a large dataset and, after some experiments, decided to change the embedding model, thus creating a slew of new vectors. The faster those are indexed, the sooner that user can resume experimenting or, if it’s ready, ship the application to production.
The VAST Data AI OS is designed to ingest continuous streams of data, and we’ve demonstrated a sustained ingestion rate of 1 million vectors/second into our vector database running on a CNode-X-based system (NVIDIA cuVS library + VAST vector database + NVIDIA RTX PRO 6000 GPU).
Of course, query performance is where any database system really earns its money. Speed and accuracy are paramount for applications like recommendation systems, where being able to better serve more users equates directly to better business outcomes. For applications like video-reasoning over public safety streams, real-time ingestion and indexing of high-dimensional data can help save lives. Many other applications also benefit from vector similarity search, including: finance, cybersecurity, genomics / life sciences, retail, and chemistry.
And for all applications, higher throughput, lower latency, and better accuracy result in increased agentic and organizational productivity. With built-in vector database capabilities from the VAST AI OS, you can avoid expensive (and scarce) memory-based indexing and the cost of a third-party vector database, in addition to enjoying significantly increased query speed — all of which increase your return on investment. Additionally, a holistic, GPU-accelerated platform eliminates the need for separate CPU resources dedicated to indexing.
We tested the VAST vector database with NVIDIA cuVS (running on a CNode-X system with NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs) against a CPU-only system using the FAISS library with 1024 dimensions, and below are our observations from running benchmarks.
The entire indexing lifecycle of the following phases — read a sample of 20% → K-means clustering to find centroid → assignment of vectors to centroids → read + write based on assignment — was 4.5 times faster on GPU than on a CPU-only approach. The K-means clustering plus assignment phase, implemented with NVIDIA cuVS APIs, especially benefitted from the use of GPUs to process a large number of vectors. An additional benefit is we observed more balanced clusters with fewer cycles when using GPUs rather than using CPUs.
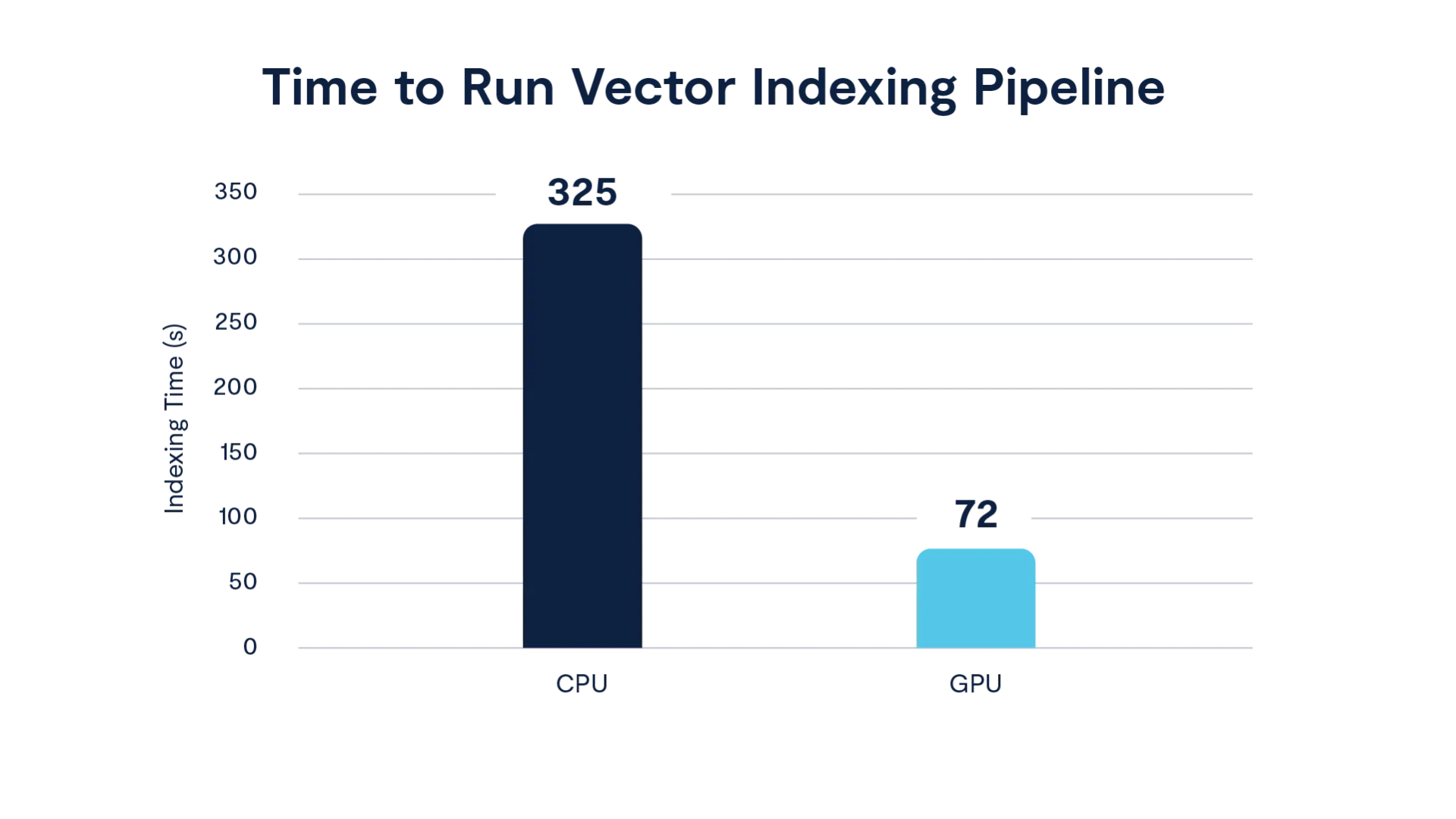
Chart: Comparison of indexing time with CPU-only vs. GPU-accelerated systems
In practice, this means a process of onboarding or ingesting large vectors that takes 10 hours using CPU resources could execute in about 2.5 hours using GPU resources. More regular, near real-time processing jobs could execute in seconds or minutes, making that data available immediately to models that need real-time access to fresh data.
Faster SQL queries for teams of AI agents
But AI isn’t only about unstructured data. As organizations begin deploying agents by the thousands or even millions, those agents are going to be reading from and writing to structured datasets at unprecedented levels. Their ultimate business value will be a function of how fast they can get results and how many concurrent queries the system can handle. Unlike with previous paradigm shifts in computing, however, Moore’s Law won’t be coming to the rescue for AI agents.
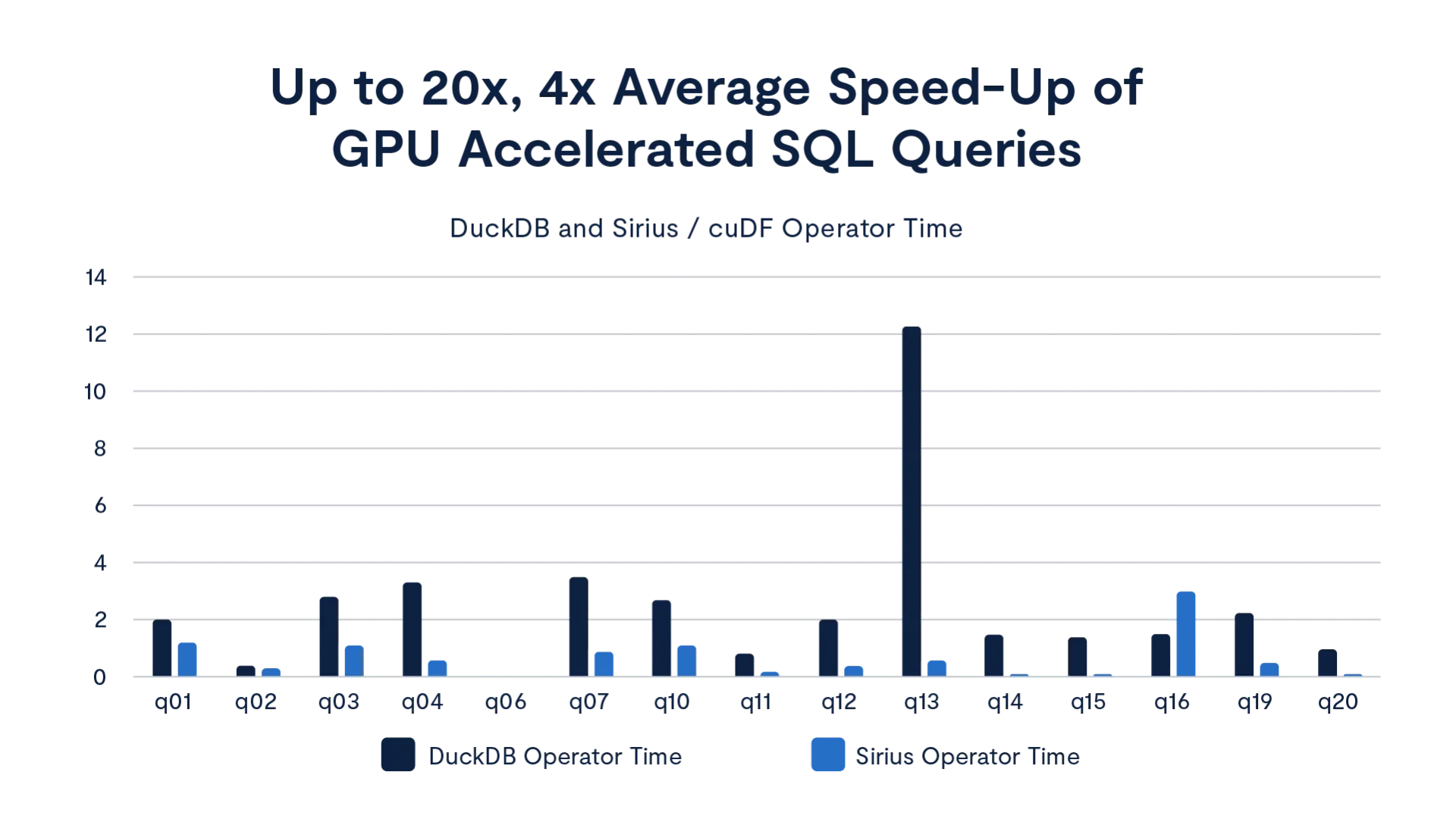
The Sirius database accelerated by NVIDIA cuDF library is optimized for the coming wave of SQL activity. It’s built on top of the NVIDIA cuDF library, which is natively compatible with DuckDB, and will be available in the VAST AI OS when CNode-X servers are released. Although DuckDB is recognized for its high performance compared to other SQL OLAP databases, early tests by NVIDIA show further speed ups with Sirius outperforming CPU-based DuckDB by up to 20x when running on a NVIDIA RTX PRO 6000 GPU.
VAST’s native SQL engine leverages the Sirius library to build GPU-accelerated operators for fast SQL-query execution. We observed significant benefits using GPU acceleration with aggregation and join operators.
This type of performance gain, driven by the inherently parallel nature of GPU processing, means more agents (and humans) can query the database concurrently and still achieve fast responses.
Continuing our work on GPU acceleration
We’re excited by the results of our work on GPU-accelerated data processing with NVIDIA libraries so far, but the work isn’t done. We plan to test and optimize the end-to-end speedups further by optimizing bottlenecks including data IO patterns. We are also excited to continue our collaboration with NVIDIA, which includes support for new platforms like the newly announced RTX PRO 4500 Blackwell Server Edition GPU. As more AI applications come online, we especially want to optimize performance for important customer workloads. If you’re experiencing pain points that could be solved by GPU acceleration, please get in touch.


