
While it should be obvious, we sometimes forget that storage system architectures are defined by technologies that were available when that system was designed. As x86 servers and 3/5” hard drives became readily available in the late ‘90s, engineers used software to turn them into scale-out, shared-nothing storage. Today, technologies like 3D Xpoint and NVMe over Fabrics allow VAST Data’s Disaggregated Shared Everything (DASE™) architecture to avoid the tradeoffs inherent in a shared-nothing system to provide all-flash performance, and a higher level of resiliency, at the cost/GB of many disk-based systems.
The basic building block of a shared-nothing cluster is an x86 server-based node. Each node contributes compute power, to manage the media and perform compute-intensive functions like data reduction or encryption, along with storage devices, most commonly SSDs today. That compute power may be dedicated to storage services or shared between storage services and applications in hyperconverged or analytics cluster.

A shared nothing cluster
Shared-nothing application systems were developed when common network technologies like Ethernet and Fibre channel had just a gigabit, or a few gigabits of bandwidth. Since a hard drive could also deliver about a gigabit per second, a server with a small number of direct-attached HDDs could access those local drives faster than it could access data across a network from a shared array or NAS system.
This model is maybe best evidenced by Hadoop implementations where MapReduce and/or Spark compute jobs are shipped to high-performance data nodes in order to eliminate I/O bottlenecks were otherwise caused by slow networks.
2000 | 2019 |
a server-storage with 12 HDDs: GB/s of IO | high-throughput 2x100Gbps NIC: ~20GB/s |
Fast-forward to 2019, and the situation has changed dramatically… Today’s networks are now two orders of magnitude faster, making shared storage as attractive as high-capacity DAS.
To provide resiliency, and protect data against node failures, shared nothing clusters must either replicate or erasure code data across multiple nodes in the cluster. The result is that a shared-nothing cluster is generally media inefficient. Replication requires twice as much media as data to provide any resilience and three times as much to ensure operations after both a controller and a device failure. Add in enough space to rebuild protection after a node failure and you might only get 25-35% of a cluster’s raw capacity in usable space.
Erasure coding can be more efficient, but erasure-coding requires the designer of a scale-out storage system to trade greater efficiency for the higher latency created writing to wider stripes HCI and other latency-sensitive shared-nothing systems limit their erasure coding to narrow stripes of roughly 4D+2P.
Introducing the VAST DASE Architecture
Shared-nothing clusters, especially those using replication, trade storage efficiency for scale and resiliency. That was a good trade when the storage capacity was cheap spinning disk but in today’s flash only, or at least flash by default, data center that inefficiency can get expensive.
Rather than use NVMe over Fabrics and 3D Xpoint to speed up an architecture designed to get the most from 1990s technology, we had the opportunity to design from a clean sheet of paper and designed a new architecture that just wasn’t possible before. The VAST Data Platform architecture that breaks the tradeoffs between, scalability, resiliency, performance, and efficiency, which is of course eventually reflected in the price.
This Disaggregated, Shared Everything architecture (DASE) is based on three key architectural decisions. Our first decision was to disaggregate, that is separate, the systems SSDs from the x86 servers that manage them. Our x86 compute nodes still run the software that turns a pile of flash and 3D Xpoint SSDs into a full-blown global namespace, but instead of sticking the storage media inside the server where they can’t be shared we moved them into resilient NVMe-oF enclosures.
Disaggregation breaks the efficiency trade-off
Since the enclosure has no single point of failure, we don’t have to worry about protecting data from node failures and can concentrate our software efforts to protecting against the much more granular individual SSD failures. To guard against SSD failures we store data in very wide erasure-coded stripes with 44 to hundreds of strips and a minimum of N+4 resiliency. Where shared-nothing systems typically require as much as three times as much storage media as you have data, VAST’s new approach to error correction provides a higher level of resiliency with a maximum just 10% overhead.
The second key decision was to connect the compute nodes to the enclosures using NVMe over Fabrics over high-performance 100Gbps Ethernet or Infiniband. Since NVMe-oF presents remote SSDs as local storage devices, every compute node can directly mount every storage device in every enclosure in the DASE cluster.
Disaggregation breaks the scaling tradeoff
You can easily scale capacity by adding enclosures and scale performance by adding or removing compute nodes. Compare that to a shared-nothing system where adding either capacity or compute resources requires adding the other. Even then, few shared-nothing systems achieve the platonic ideal of a single building block. Most shared-nothing vendors have fast nodes, small nodes, large capacity nodes and complicated cookbooks about which types of nodes can be in the same cluster complicating the purchasing, and expansion process for customers. With DASE you never need to buy capacity when you need performance or compute power when all you need is capacity.
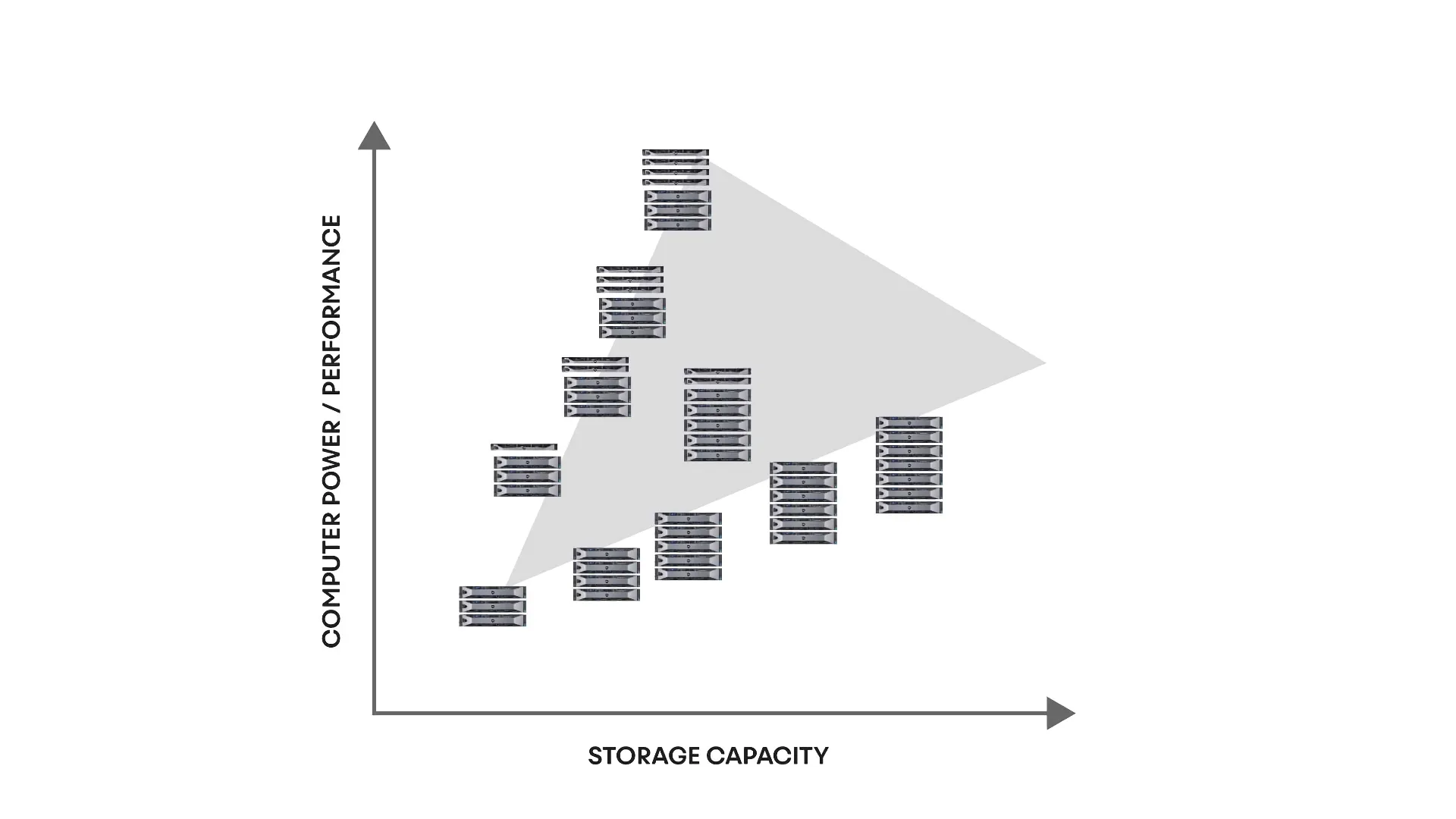
Shared-Nothing systems scale capacity and compute
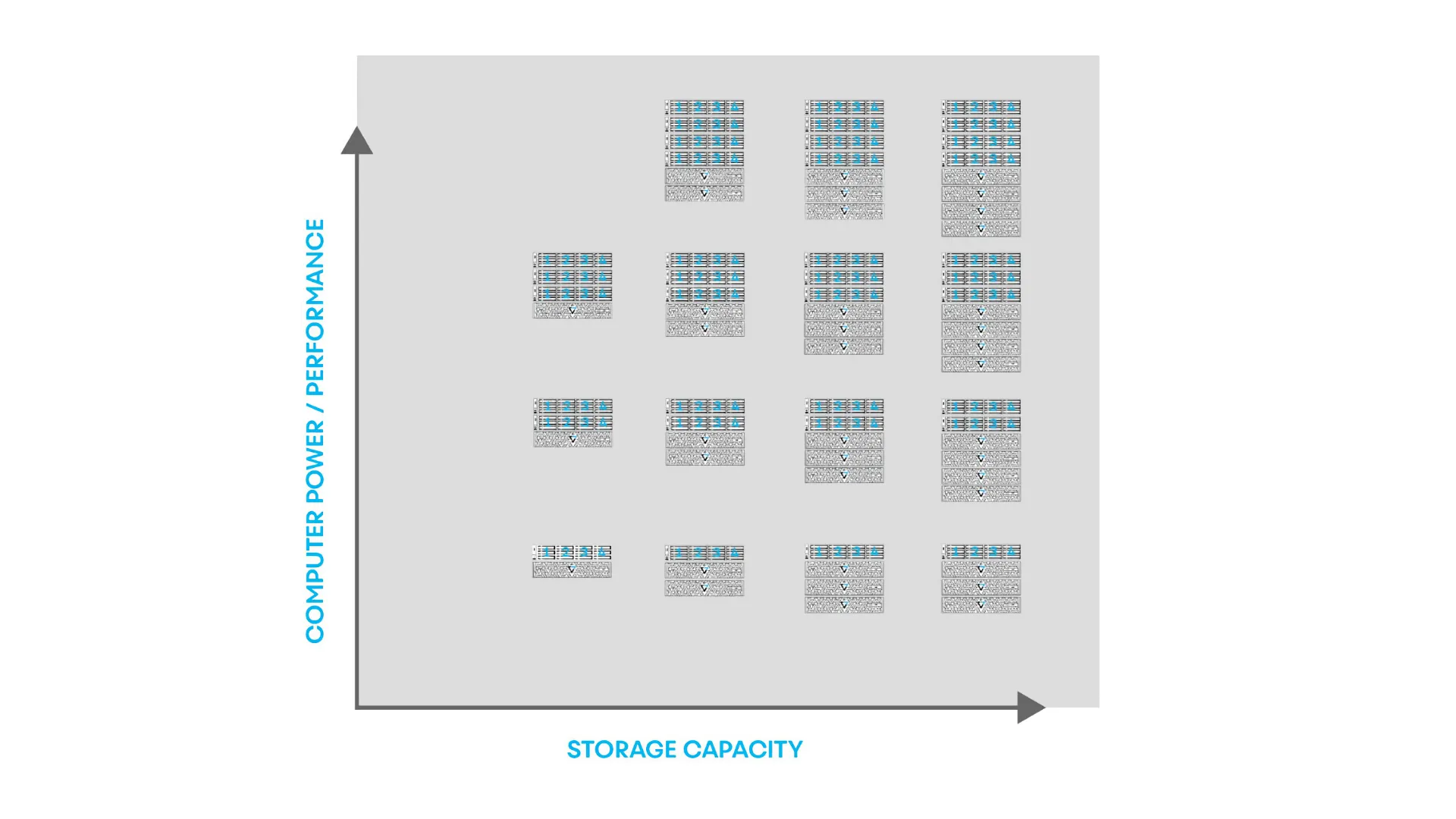
DASE allows you to scale independently
Disaggregating, shared-nothing nodes into compute nodes and resilient enclosures means the compute nodes can share access to the 3D Xpoint and flash SSDs essentially as fast as they were local, avoiding the cache consistency complications and efficiency tradeoffs shared-nothing systems have to make while freeing users from having to tradeoff capacity, storage performance, and compute power when selecting from a myriad of node configurations. Instead, users can just add compute nodes for performance and/or enclosures for capacity.
Our final key is storing all the system’s metadata, in fact, all the system state information, on 3D Xpoint in the NVMe-oF enclosure. When the system receives data - that data, and it’s associated metadata is written to multiple 3D Xpoint devices before the write is acknowledged.
With all state information stored in the enclosures, the compute nodes are stateless, eliminating the need for NVRAM, batteries and the software complexity of maintaining cache coherence across a cluster. It also means that there’s only one shared set of metadata that serves as a central source of truth allowing any compute node to process a request without the forwarding and other inter-node traffic shared-nothing systems need to process requests for data they shared across multiple nodes.
Summing Up
DASE breaks the trade-off of efficiency for resiliency
DASE minimum protection N+4, maximum overhead 10%
Shared nothing typical protection N+2, overhead 25-200%
DASE breaks the trade-off of scaling compute and storage together
Scale compute by adding compute nodes
Add capacity by adding enclosures
DASE breaks the trade-off of resiliency for rebuild impact
Rebuilding a failed device requires reading a maximum of 1/4th the survivors
Erasure coded shared nothing systems must read all the data
Of course, there’s more to a storage system than just it’s architecture. Our disaggregated shared nothing approach breaks the tradeoffs inherent in shared-nothing designs but a great architecture isn’t enough. We’ve got a few software tricks up our sleeves, like data reduction more efficient than compression and deduplication, to run on top of DASE but they’re the subject of another blog post.


