
Version 5 is here
What’s the theme? Product announcement themes are often sought out by marketing teams as they look to create an organizing story to support a product launch. Often times, software releases are hard-coded long before marketing teams get to thinking about themes, so themes can often feel a bit forced or constrictive.
It’s that time of the year when we’re ready to drop our newest and greatest product release… version 5. When I put a mirror in front of our next biggest release ever… aka version 5.0… two themes are reflected back to me:
The list of features is long, and each has a tight linkage to user stories that come from customers who are challenging us to help them get more value from our Platform. This is not capability being developed in a vacuum, our R&D exists to delight customers. As such, the variation of features in version 5 is a direct reflection of the diverse and progressive customer base we now serve.
In general, I also see the beginning of a new chapter for VAST. Here, the capability being put into place is foundational to the grander product vision we laid out in our Build Beyond. We like to think that we keep very little secrets, so now that the product vision is out in the open… we can talk openly about how all of the pieces come together.
The amount of new capability in 5.0 is just massive, so let me try to bucket every significant feature into topics that you can click through to. As you click down, I’ll work to provide a little color and context where necessary.
| DataSpace Cloud Enhancements |
|
|
| DataStore Protocol Enhancements | SMB |
|
| S3 |
|
|
| DataBase Enhancements |
|
|
| Platform Security Enhancements |
|
|
| Performance Enhancements |
|
|
Simpler, Safer Cloud Deployment
Cloud-wise, we’re on a journey to provide a best-in-class deployment experience for customers who want to deploy standalone clusters in large Cloud Service Provider (CSP) environments, or for customers who want to federate their namespaces into large CSPs using the VAST DataSpace.
In support for this mission, we’re offering two new capabilities that customers can now use to make their cloud deployments simpler:
-
The VAST Multi-Cluster Manager: Think of this as something of a centralized tool that can easily spin up and manage VAST clusters in your cloud of choice. This is a container that can deploy within a cloud environment (that is in your VPC) or is a new feature in the VAST Management Service (VMS) that runs off of an existing VAST Cluster.
Multi-cluster management is responsible for deploying and managing cloud clusters as well as creating data sharing and replication relationships between clusters, including:
- Creating global namespace peering via the VAST DataSpace
- Establishing and monitoring single-site replication and group replication
- The creation and distribution of global (writeable) snapshots
This is the one ring to rule them all all them (clusters).

-
AZ-Wide Data Availability: Our first foray into cloud involved a relatively simple instance that could be deployed from a single EC2-style of volume. Ephemeral storage volumes are cheaper than persistent ones, but they aren’t able to survive the outage of any one availability zone. Our early cloud version was ideal for burst computing, but not long term data storage. For this reason, we now persist a second copy of data to persistent data stores. For example, in AWS:
- Metadata and write buffer data is mirrored into EBS
- Data is persisted into AWS’s S3 service
So the active data remains cheap and fast on EC2 volumes, and that data is protected from an AZ outage by also being recoverable from a persistent and cost-optimized tier of storage.

More Capability for SMB Users
I’m not sure this one needs a lot of attention since the SMB features are self-explanatory. Now that we support Previous Versions, Access Based Enumeration and Server-Side Copy, we’re in a much better position for home directory users (who value our scale and multi-tenancy) as well as media customers who want to use VAST for all of their workflows.
Accelerated DataBase Performance
Since 4.6, the VAST Data Platform supports a tabular data store designed to accelerate every aspect of database management services – unlimited ingest/insert scale, easy table updates and query performance optimized for how NVMe drives want to be exercised, resulting in not just 100x faster queries vs HDD-based data lakes, but a far simpler data engineering experience. So, here’s what’s new since 4.6:
-
Semi-Sorted Projections: OK, so what’s a projection?
A projection is a table that is derived from a parent table and contains some subset of its data. To be useful, the projected data is manipulated in a manner such that querying it will be faster for relevant queries.
An example of this in use might be a projection that contains one of the columns from the original table that is organized in a sorted manner. Other examples include storing an aggregation of a column or some grouping of it. A projection can also be the result of any query on an original table that is being stored persistently as a projected table.
What’s the result? For presorted data, customers see a 1,000% increase in performance for queries that can benefit from filtered projections.
-
Support for Trino Version 420
VAST now offers a pushdown plugin for customers looking to accelerate Trino release 420. 420, on its own, offers a number of advantages vs release 375 (which we also support), including faster query response times, support for new types of data aggregations and support for new numeric literals.
Enhanced Security & Usability
OK, buckle up. There’s a lot here…. Consider that VAST is balancing the needs of the world’s largest banks, the world’s largest technology companies, the world’s largest governments and the world’s largest service providers. Zero-Trust is paramount to our offering, and the following details our newest efforts to make enterprise infrastructure safer and simpler for our large and diverse customers.
-
Audit Logs, now stored and searchable in real-time from the VAST DataBase
The VAST DataBase has pioneered a next generation approach to table data storage that allows the Platform to insert data at rapid speed (like a transactional database) and query data as fine-grained columns so that you get the best analytics performance (like an exabyte scale, all NVMe data warehouse). This unique blend of rapid data ingestion and real-time query performance makes this solution an ideal platform for real-time event capture and monitoring… so, logs.
Starting with 5.0, customers are now able to use the VAST DataBase as a log capture and analytics platform. To learn more, our very own Scott Howard, VAST’s Principal Solutions Architect, breaks down the new audit capability in this video.
-
Real-Time Anomalous Event Detection
What’s an anomalous event? Well, this is somewhat in the eye of the beholder. Starting with 5.0, our remote cloud-based management service (Uplink) now features machine-learning based event processing to understand anomalous behavior that can indicate rogue user behaviors as well as security threats such as ransomware attacks.
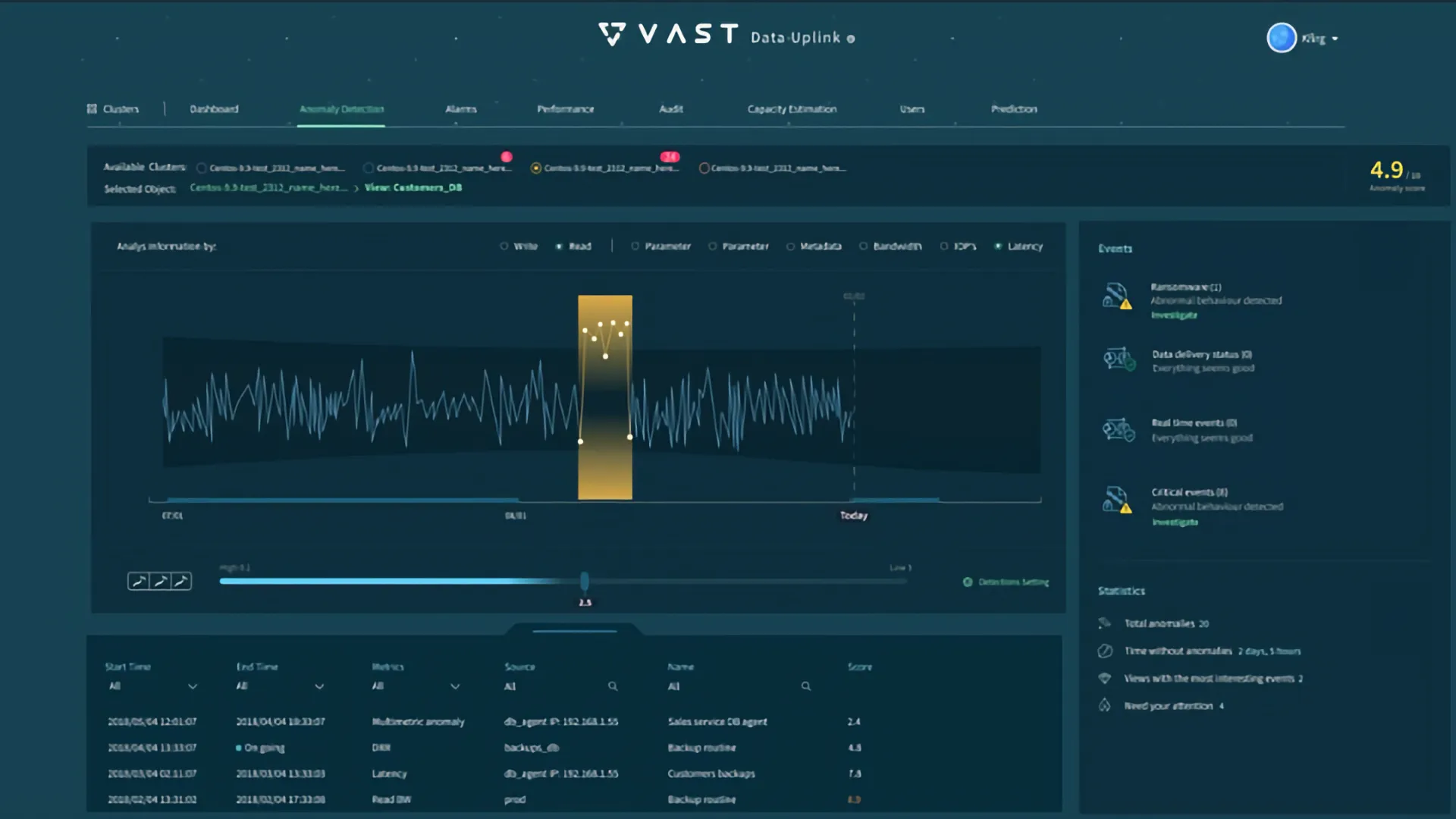
The system can be instrumented to alert based on the policies our customers set – but dramatic swings in performance, metadata operations or data reduction can trigger flags that administrators will be guided to investigate. To learn more, our very own Peter Kogan (a VAST Senior Software Engineer) breaks down how we use machine learning to better identify anomalous user behaviors in this blog here.
-
And other stuff …! (largely self-explanatory)
- FIPS 140-3 Certification
- Cross-Forest Trusts and One-Way Trusts
- Way more multi-tenancy enhancements that we don’t have time for here…

Multi-Dimensional Performance Enhancements
Finally, 5.0 is a big expression of our constant quest to make user access as fast as possible and for applications to flex compute infrastructure to achieve the best possible compute efficiency. As we know, interactive (user) services also influence user happiness much more than applications that use VAST for batch workloads, so we’ve paid particular attention to making interactive services faster.
-
User-Level Quality of Service
For our performance-centric customers, user-level QOS is something of a unicorn feature that many systems managers have sought and few vendors have ever delivered on. We’ve been in the QOS business for some time, but user-level controls put guard rails around user behaviors that make it possible for organizations to limit the impact of any one power user ruining the data access experience for anyone else.
Our very own Rupert Menezes (Field CTO for AI and Emerging Technologies) details this new capability in his very first VAST Data blog post.
-
Block Caching
Forever, read I/Os have come from persistent NVMe infrastructure in the VAST Data Platform. In 5.0, we’re now implementing a block-based read cache such that prefetched and repeated read events see an acceleration that can be 10x vs the NVMe case. For activities that constantly go back to the same directories, buckets or tables – the new Block Cache will deliver an extraordinary level of acceleration.
-
Dynamic Similarity Execution
While VAST’s Similarity-Based Data Reduction has proven to deliver revolutionary levels of capacity efficiency, not all data sets reduce equally. Historically, Similarity has been applied in a binary fashion – either the system finds similar blocks, or it doesn’t. In cases where Similarity is established and blocks become globally compressed, each read operation of a Similarity-reduced block requires two lookups (one to the reference block and the other to the delta) – and this happens regardless of the amount of reduction.
With 5.0, the Platform is now conscious of the fact that customers may not want to pay the additional latency penalty of two read operations for a small gain in data reduction… so, we now set thresholds where the system will decide (dynamically) if it makes sense to apply Similarity reduction by first determining the overall data reduction benefit. If the juice isn’t worth the proverbial squeeze, we don’t squeeze the data in this case. Thresholds are administrator-definable, and our recommendation is to exclude Similarity when savings are under 5%.
-
Increased Read/Write Thread Parallelism
For a number of I/O operations, including the provisioning of read/write paths as well as how metadata is handled, we’re now allocating more threads from server CPUs to handling read write I/O – resulting in a dramatic (up to 30% improvement) in random I/O operations.
-
Reduced Synchronous RPCs for Metadata Transactions
By handling metadata transactions more efficiently, we’ve now improved metadata transactional latency by 10%.
This isn’t an exhaustive list… but it’s the highlights. For customers, check out the release notes to learn more… and please keep your feedback coming, we appreciate you.
Best,
Jeff


