

In the increasingly noisy space of enterprise AI, where real-time performance fits the over-promise/under-deliver metric, VAST’s InsightEngine presents a compelling redefinition of what AI infrastructure can be.
VAST co-founder Jeff Denworth’s GTC 2025 talk unpacked this for a packed room, offering a serious critique of how enterprises are currently approaching Retrieval-Augmented Generation (RAG).
As Denworth explained: “Most people are still in the research phase, the research phase that basically takes a few data sets and runs it through a pipeline... and they haven't really played the whole scenario all the way out.”
In other words, this isn't just about experimentation, it’s about failing to plan for the inevitable scale and complexity of AI systems that are moving from pilot to production. InsightEngine was built to fill that gap.
Denworth outlined a scenario that might sound dramatic but is rooted in a clear trajectory:
“You’re talking about something in the order of 40 trillion vectors just for a 100-petabyte enterprise... No vector project up until now has ever thought of needing to actually parse through that data at enterprise level of scale.”

“The Trillion Vector Challenge.” It’s not just theoretical scale—it’s a real-world breakdown of how enterprise data types translate into vector counts. Across 100PB of typical enterprise data, we’re looking at 40 trillion+ vectors once things like chunking, speech-to-text, and frame sampling are applied. The headline isn’t just volume—it’s that every byte of enterprise data, across modalities, is now on the path to being indexed, embedded, and made retrievable in real time. And legacy infrastructure simply isn’t built to handle that.
With the rise of agentic systems and real-time inference, data volume isn't just a storage problem—it’s a performance and architecture challenge. InsightEngine is engineered with the assumption that generative AI won’t just support human users—it will increasingly replace them in key workflows.
"If you have these models that are now approaching the intelligence of a STEM graduate, then the natural conclusion is that they will also be used for data engineering.” These systems will need immediate access to clean, current, and contextually rich data. Anything less, and the system stalls.
That maps perfectly back to VAST, with an architecture that avoids the old paradigm of partitioned, node-specific storage. Instead, it delivers a shared-everything model that is rooted in NVMe-over-Fabrics. This enables every CPU to operate with a consistent, real-time view of all the SSDs in the system without requiring any cross-talk or coordination.
As Denworth highlighted, “Every single CPU has the same view of the SSDs within the cluster... without having to talk to any other CPU in the cluster.” This structural change enables a platform that can support trillions of vectors without collapsing under the weight of its own index.
Equally important is how InsightEngine handles vector search. Most systems degrade as the number of vectors increases, but this one doesn't. Denworth is unequivocal: “You need to be able to search in constant time.”
To do that, VAST relies on new persistent-memory data structures that eliminate the need for bulky, memory-based indices. The result is consistent performance regardless of data scale.
Here’s the real story that often gets missed: Real-time performance doesn’t end at read speed.
The goal of VAST’s system is to ingest and classify data at the speed of business. Traditional systems, built for batch loading and consistency, often struggle to keep up with real-time workflows. VAST flips this on its head by designing a system where ingestion is as fast as querying.
“You need distributed systems that are not only easy to read from, but they also have to be super fast to write to,” Denworth said, pointing to the need for continuous, low-latency data flow.
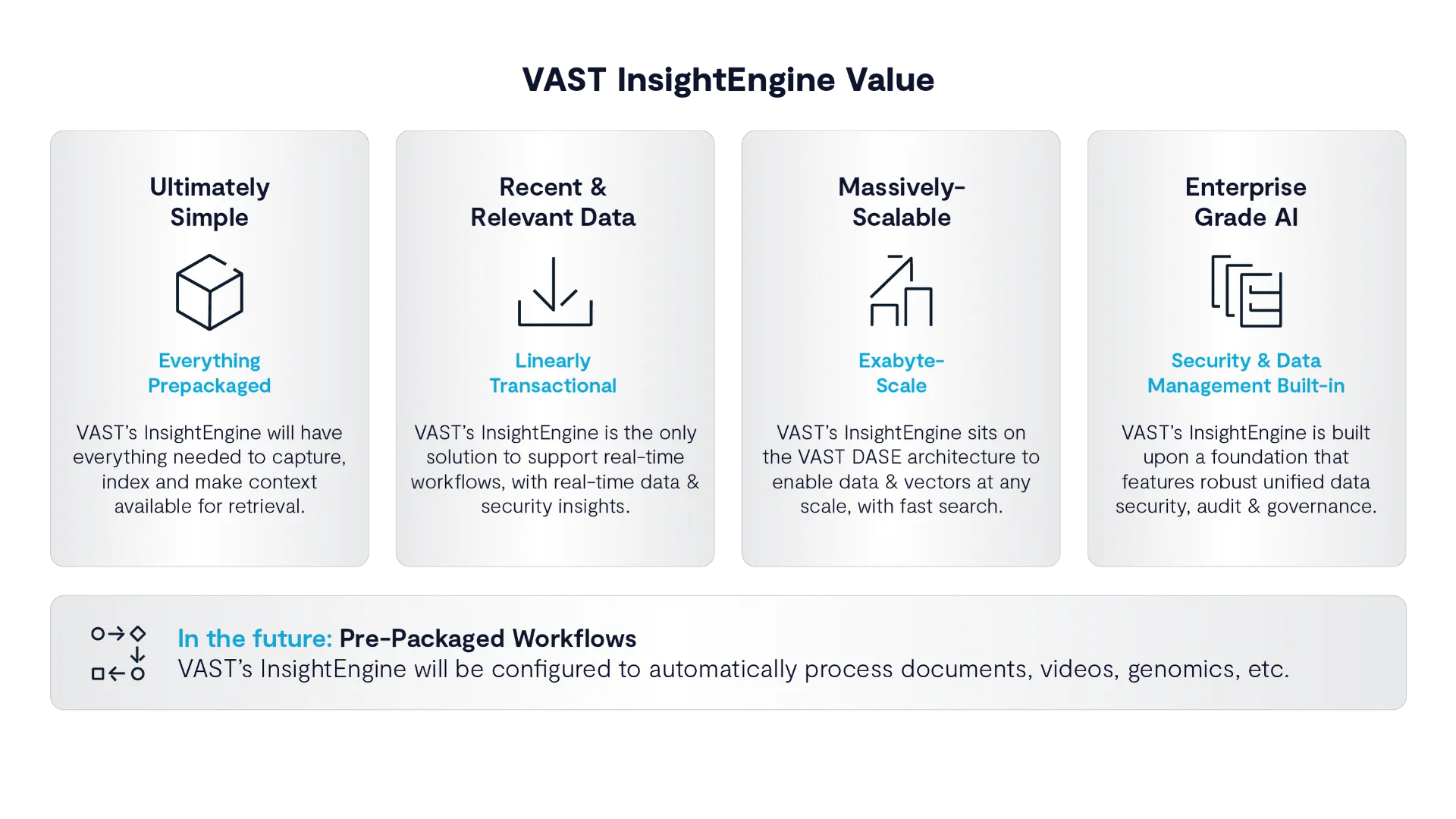
You’re looking live at the real-time loop that defines InsightEngine’s architecture. Structured and unstructured data (not that you need to care anymore) flow in, get immediately classified, embedded, and indexed through a pipeline powered by NVIDIA NIM, and land in a unified data platform where vectors, tables, and graphs are all governed under what’s we’ll get to in a moment– a single atomic security model.
On a separate note, while it’s easy to get caught up in compute and data movement at GTC, perhaps the most distinctive feature of the InsightEngine is how it treats security. In VAST’s design, access control is not layered on top of data—it’s woven into the structure of the system itself.
“You change the [access level controls] and those are instantaneously applied against the entire vector space... So nobody can ever make a query against a piece of data that isn’t totally contiguous with the underlying source data.”
The system maintains a unified access model where every file path, vector, and user permission is enforced at runtime. It’s a thing of beauty and worthy of notice.
Taken together, InsightEngine isn’t just another platform—it’s a full-stack environment where data is ingested, indexed, embedded, and made queryable in real time. Structured and unstructured data alike flow through the same pipelines, governed by a unified policy model, with performance that holds steady even as data volumes spike.
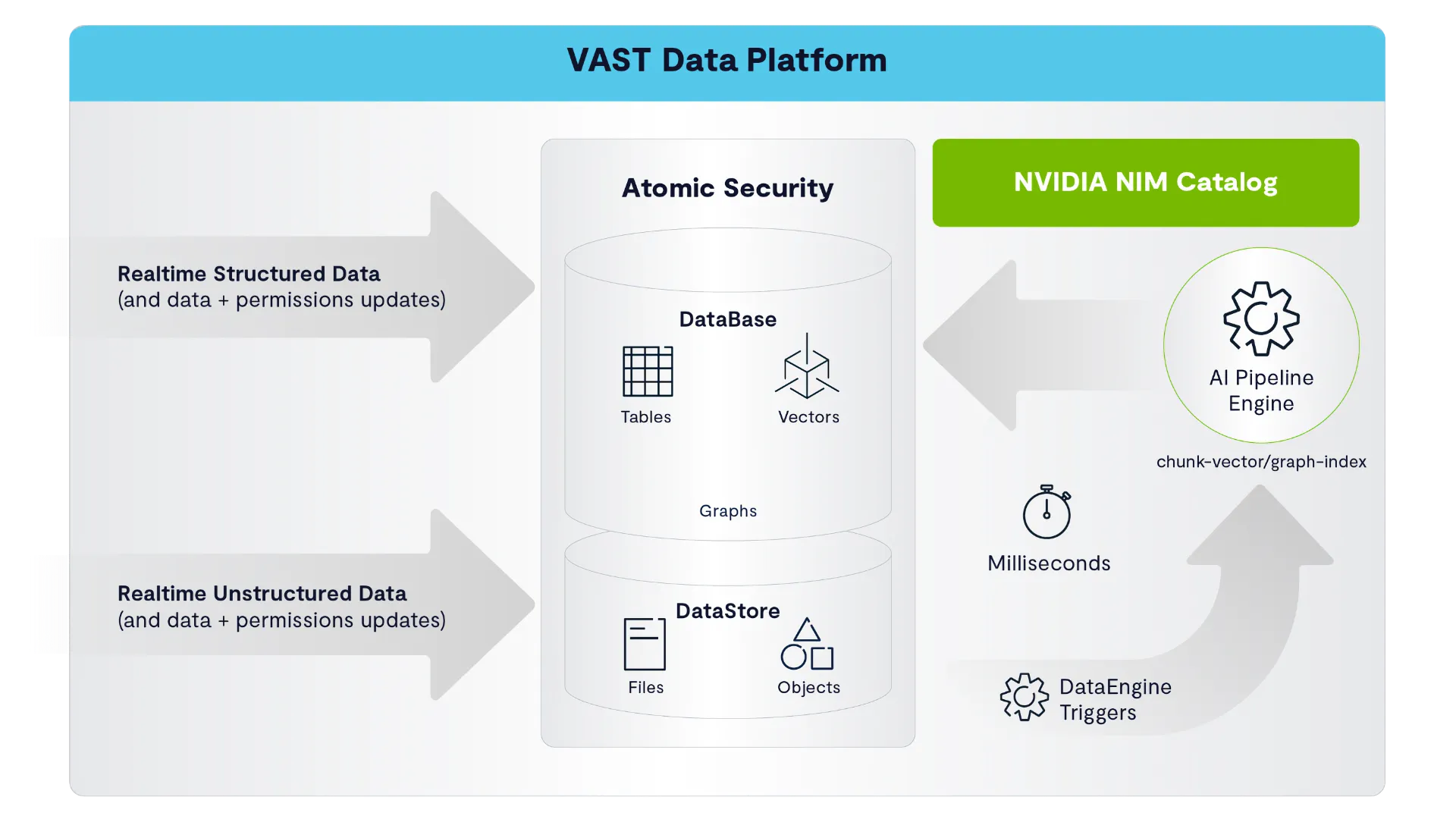
VAST InsightEngine is simple, real-time, massive, and secure—out of the box. Everything’s prepackaged so you can go from raw data to AI-ready context without duct tape. It handles scale, respects governance, and keeps things fresh with real-time updates. And yes, pre-built workflows for stuff like docs and genomics are on the way.
This is what a real-time AI foundation looks like: unified storage and compute, trillion-vector scale, sub-second inference, and strict security—all in one system.
That got me thinking: the name InsightEngine isn’t a metaphor as I once envisioned it. It’s a literal engine for machine understanding—and it’s built to run at enterprise scale.


