
By now you’ve probably seen the benchmark.
It’s been shared, side-eyed, debated in Slack threads, hailed and critiqued in equal measure.
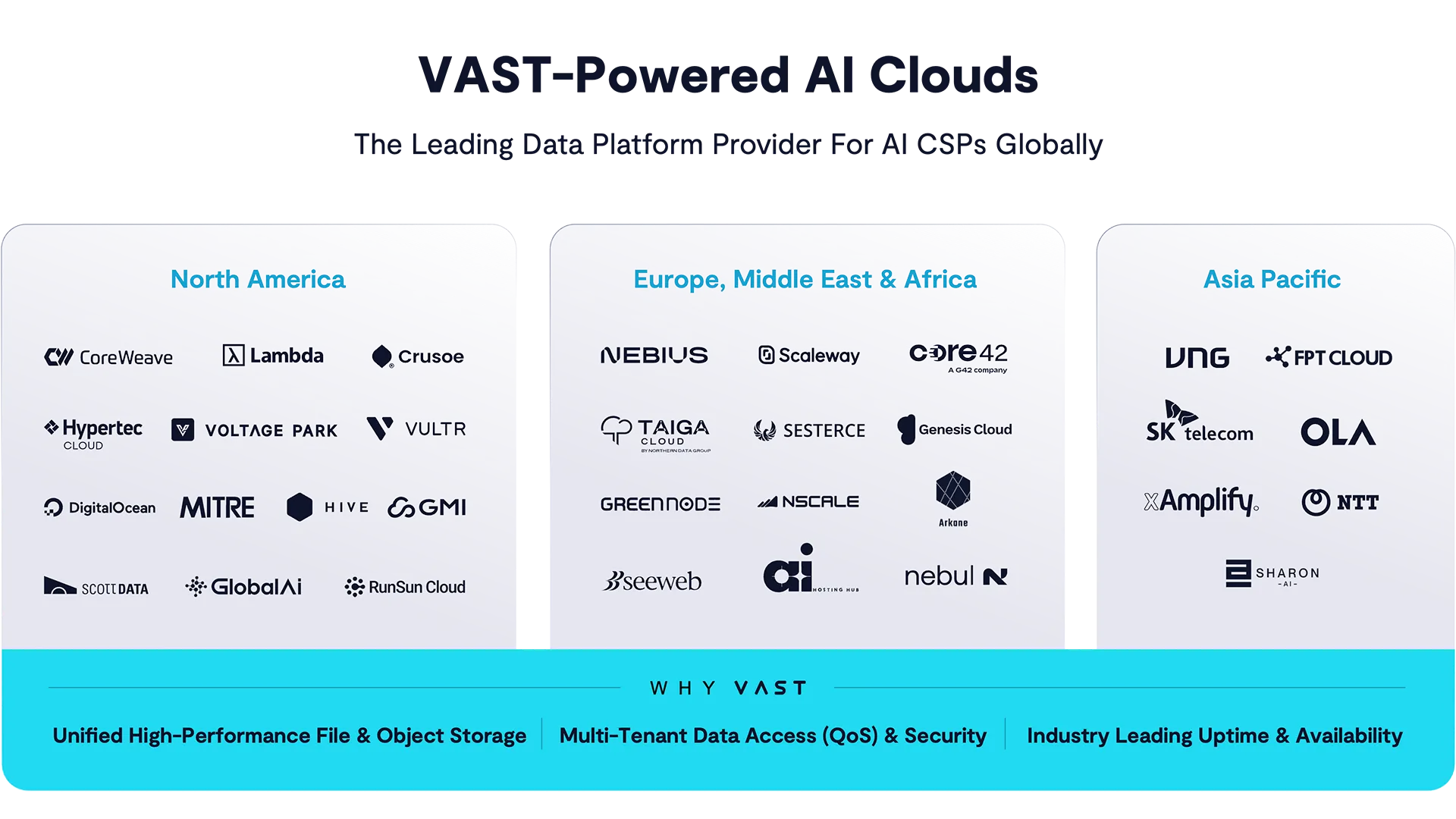
The full-stack rating of GPU cloud providers is the first attempt we’ve seen to classify the AI infrastructure landscape in a comprehensive, technically grounded way.
By categorizing AI CSPs into clearly defined tiers the ranking aims to guide users through practical, performance-based insights, with the goal of raising the industry’s standards and helping users navigate an ecosystem muddled by hype.
But let’s skip the ranking drama and zoom out for the bigger picture.
What matters more than who landed in which tier is who showed up across the board. Because when you peel back the curtain on this matrix of AI-native providers, one pattern emerges: a staggering number of them have chosen VAST.
And it’s not just the marquee names, but an entire cohort of fast-growing, design-forward infrastructure companies.
Since we’re making big picture connections here also consider this: These are builders, not buyers. Born in a post-GPT world, these GPU cloud upstarts had no technical debt, no twenty-year-old IT hangovers to navigate. They could choose the architecture best suited to the specific needs of now, and overwhelmingly, one by one, they picked VAST.
The first question is: why?
Let’s start with multitenancy—the most under-discussed and over-required feature in modern AI infrastructure. Really, without robust multitenancy, you don’t have a cloud, you have a colocation site with delusions of scale.
VAST’s approach is grounded in actual architectural separation—access, data, and admin isolation are enforced not just through software, but through an intentional design that aligns with how AI clouds onboard customers.
CoreWeave, for example, spins up dedicated clusters for super-tenants, but for onboarding net-new GPU customers, say those just looking to trial-run 100 GPUs in a shared environment—multitenancy is everything.
VAST lets infrastructure providers logically carve up hardware into tenant-specific allocations with real guardrails: per-tenant capacity limits, performance SLAs via rock-solid QoS, encryption key isolation, and the ability to provision and monitor storage volumes entirely through its signature Kubernetes-native workflows.
This is not just container orchestration theater. VAST plugs into Kubernetes with secure credential injection and volume provisioning, letting the end customers access and manage their storage environments without touching underlying infrastructure.
And importantly, tenants see only their data—thanks to network-level identity enforcement, security is tied to where requests originate, not just what those requests claim to be.
Add in S3 and NFS running at full speed on the same hardware, tenant-specific observability and billing, and real, actual enforced performance isolation, and you get a system where multi-tenant doesn’t mean “everyone’s racing on the same track” - it means every tenant has their own lane.
The other unsung hero is uptime: The thing no one markets but everyone bleeds for when it fails.
VAST’s customers are bound by SLAs—to their own customers—and they don’t get to chalk up downtime to maintenance windows, which are fine for supercomputing facilities and universities but inexcusable in the cloud. Across our fleet of exabytes of systems we manage, the average uptime is now 99.9991% since the last 6 months. That’s 4.7m of average downtime in a year - which is pretty spectacular given that some of these systems are throwing off 100s of megawatts and intense application demands from multiple tenants.
What the CSPs on the list know is that VAST delivers always-on upgrades and expansions without rebooting or interrupting access—meaning they can scale or patch without ever paying uptime penalties. That kind of reliability is not just a checkbox, it’s the entire sales pitch when you're charging enterprise customers for AI model execution by the minute.
Security is no less vital.
In an age where AI clouds are increasingly serving the regulated and compliance-bound, VAST offers a layered, standards-based security stack.
For instance, per-tenant encryption keys allow for true cryptographic separation. Should a tenant want to delete all their data, the safest method - rotating their key - is trivially easy. Access policies are enforced not just by ACLs but by topology-aware network-level isolation. And admin isolation means even anointed tenant managers can issue their own API keys, set usage policies, and track consumption.
All of it’s auditable, observable, and works across both file and object protocols at scale.
Ultimately it’s this robustness - the architectural kind, not the marketing kind - that is the real story behind the benchmark.
It’s not that these AI cloud providers all happened to pick the same storage vendor. It’s that VAST, underneath the hood, is quietly enabling the kinds of operational models—shared GPU pools, asynchronous file-heavy workflows, Kubernetes-native provisioning, and performance predictability—that turn a collection of racks into a real AI cloud.
There’s more on the way too: VAST is supporting new, higher-level workloads: SQL-intensive model evaluation, real-time KV cache retrieval, even vector search and event streaming. These aren’t future features—they’re happening now. And they’re only possible because the architectural substrate is flexible and performant enough to support them.
It’s the big things–and it’s the attention to detail, focusing on what CSPs need that makes VAST the choice among the major AI clouds. Here’s one more example: data reduction. Yes, it’s a dry topic. But it’s worth paying attention to, especially from a TCO perspective. Across VAST’s AI customers, Similarity-based data reduction averages 2:1 for text, multi-modal and robotics training data.
That kind of footprint shrink translates into serious power, rack space, and SSD savings. And when you layer that onto erasure coding overheads as low as 3%, the TCO case starts to look hard to argue with. For Neoclouds, these unique advantages translate to additional gross margin streams that allow them to offer very competitive services.
So no, we’re not going to parade a screenshot of the ranking matrix and declare victory. But we are going to celebrate the fact that nearly every major AI-native CSP that’s been built in the last ten years—those not shackled by legacy architectures—chose VAST. That’s not a fluke. That’s architecture speaking for itself.
And if you’re building a GPU cloud? You might want to join the pack.


