
As we embark this week on ISC 2023 in Hamburg, Germany, we at VAST are again excited to sponsor and exhibit at the annual HPC event. HPC/AI workloads were VAST’s initial use case when we started shipping product in 2019 and to date HPC makes up about half of our business. Talking with users and helping them solve their challenges remains one of the best parts of my job, nearly 20 years since I joined the HPC industry.
When I joined the Fraunhofer Center for HPC back in 2005, where I designed BeeGFS, I interviewed a lot of HPC researchers to find out what they expected from a new parallel file system. Today I can say that the essential user demands have been the same all the time: fast access to large and small files, sequential and random. Back in the days this applied primarily to the files of their current project at hand, but nowadays in the data-centric era of AI and modern analytics, it applies to the whole archive of files for continuous training.
The fundamental problem was and is that software has been bound by the capabilities of spinning disk storage, which is just inherently slow for small random reads and high access concurrency.
Consequently, users have had to spend a lot of time and effort on trying to rewrite their applications into doing less random and less concurrent storage access. This was necessary to improve the application runtime with spinning disks, but it also severely limited the possibilities to evolve HPC applications through new algorithms.
Interestingly, this somehow seems to have created the impression over the years that HPC is primarily about streaming I/O, but that’s not the case. Some very significant advancements in HPC become possible when the file systems are no longer limited by spinning disks and when the users understand that this not only makes their current workload run faster, but finally enables them to no longer worry about random access patterns.
“VAST has not just changed the way we store data – it is changing our relationship with the data” are the words that our customer DUG used to describe these new possibilities after switching from Lustre to VAST. This statement perfectly captures the essence of this new data-centric era in HPC, where a fast compute cluster is just less useful for modern applications if it doesn’t have access to the right storage platform and data services.
VAST offers an NFS-based multi-protocol architecture for affordable large-scale all-flash systems that can meet both traditional HPC as well as emerging AI & analytics requirements, resulting in better agility, performance, and scalability of the converged HPC & AI environment while reducing complexity through enterprise-grade data services tailored for users' needs.
Some readers might have done a double take on the above paragraph. NFS for HPC? Certainly yes. Most storage sysadmins in HPC will have tried NFS servers at some point because they are so nicely convenient and simple to access from anywhere. This typically didn’t go well, which created another common impression: NFS is slow.
Consequently, the HPC community turned to the less convenient and less feature-rich parallel file systems for scale-out performance.
But NFS is just a protocol specification. This specification is not fast or slow. It’s the service implementation behind the protocol specification that makes the result fast or slow and that provides scale-up or scale-out. VAST is a full scale-out performance architecture for affordable large scale flash systems. And we still care very much about performance with NFS and have demonstrated scale-out performance to systems of over 100PB in size and over 160GB/s throughput for a single NFS client mountpoint.
In a VAST system, a single client mountpoint can talk to just one of the several servers in the system (with different clients being automatically assigned to different servers) or also in parallel to multiple servers through our NFS multipathing technology. Either way, every server in a VAST system provides access to the full namespace, because it is connected to all the drives in the backend and thus can also do striping and erasure coding across all of them.
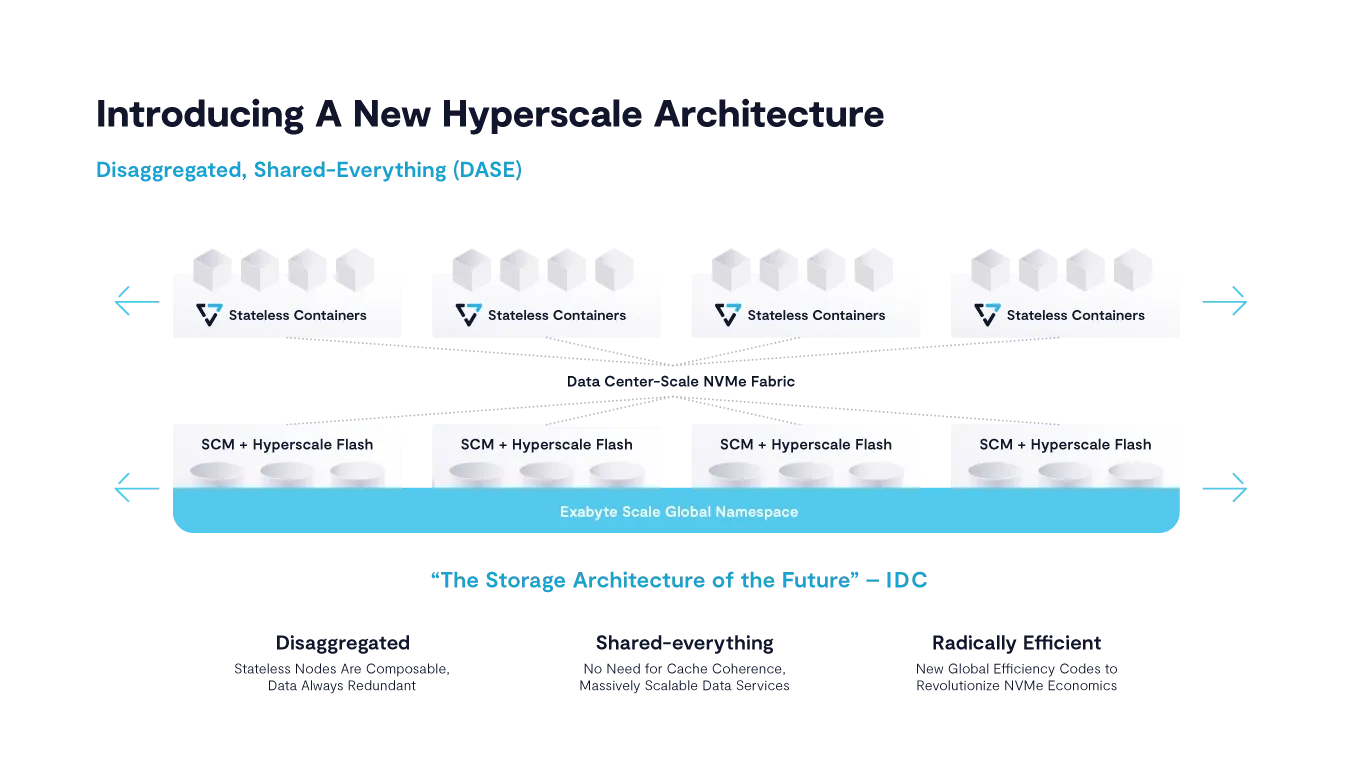
Add to that all the other features that you were always dreaming of, like support for fully consistent snapshots; native RDMA (IB & RoCE); the ability to connect the system easily to different physical cluster networks; built-in replication of individual subdirectory trees for disaster recovery; multi-tenancy; non-disruptive upgrades without the need for any manual commands on the console; quality of service controls; a warranty on the flash drives that is independent of the written amount of data; live statistics for individual users; and support for additional protocols like SMB and S3 to access the same data with consistent access permissions across the protocols. That all together would be a nice high-level description of VAST, but we’d still only be talking about the tip of the iceberg.
(For a detailed third-party view of how high-performance NFS-based infrastructure is reshaping prior HPC community assumptions, read this IDC white paper.)
So with VAST, HPC users get:
A new exabyte-ready scale-out architecture for NFS/SMB/S3/SQL
All-flash performance for fast random access to all data without noisy neighbor problems
An always-online HPC storage cloud with NAS ease of management and non-disruptive upgrades
Consolidation of HPC and AI/ML workloads
Reduced operating overhead and costs
But most importantly: Researchers and data scientists that are free to run and invent modern algorithms without being bound by the mechanics of spinning rust
That’s why VAST Data has earned trusted provider status for many HPC-focused organizations, including higher education and government research firms, life sciences organizations, and financial services companies.
Let me know if you’d like to discuss how VAST Data can help streamline your workloads and generate faster results.
Please come visit the VAST booth at ISC (D418) and I’ll be happy to discuss your specific HPC and AI workload challenges. See you in Hamburg!

