Deploy all-flash infrastructure for all data sets. VAST’s new advancements in commodity flash management, data protection and reduction deliver a lower TCO than hybrid storage alternatives.
Overview
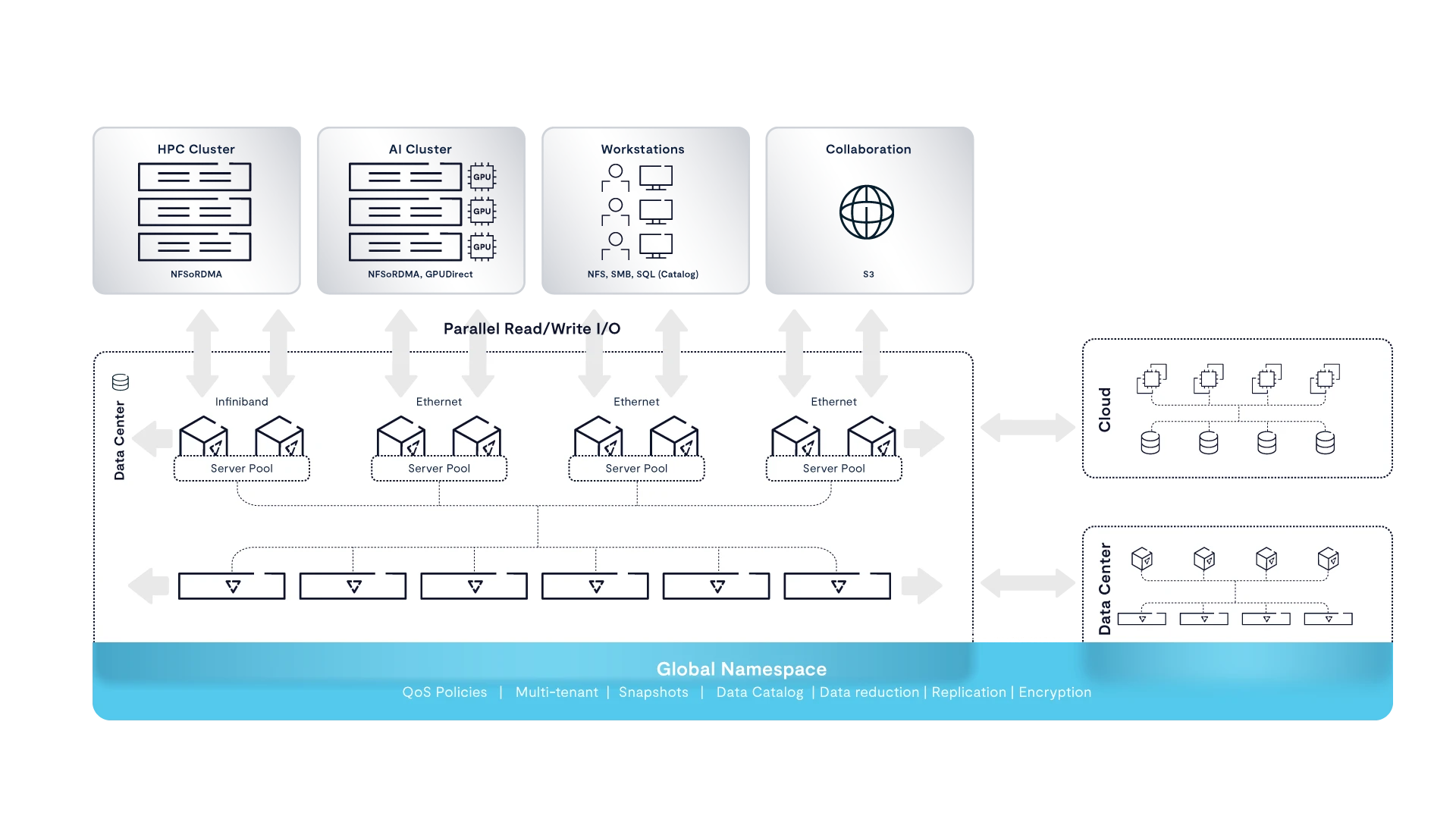
The VAST Data Platform accelerates HPC by delivering the performance and scale of parallel file systems with the simplicity of NAS, all at archive economics. Powered by VAST’s DASE architecture, our customers build scale-out systems delivering TB/s and millions of IOPS of performance without the rigidity and overhead of legacy architectures.



Consolidate scratch and nearline tiers to a single high-performance platform that eliminates data migrations and future-proofs your data for AI workloads. The VAST Data Platform fuels innovative HPC teams to compute on exascale data sets from edge to cloud with unrivaled simplicity.
Taking on the world’s most complex computational workloads required a relentless focus on performance at scale that lead HPC teams away from well-known storage protocols like NFS and to adopt specialized parallel file systems that provided support for parallel streaming operations. Parallel file systems like Lustre, GPFS, and BeeGFS were accepted as the only viable option for HPC workloads, and the complexity of custom software clients, disruptive upgrades, expansion, and customized tuning as unavoidable tradeoffs.
Enter the VAST Data Platform, with the revolutionary disaggregated, shared-everything (DASE) architecture that builds an inherently parallel foundation for world-class HPC performance and scalability. Leading HPC teams are proving that with VAST they can get all the performance and scale of parallel file systems via standard NAS protocols like NFS while gaining unparalleled simplicity and reliability.
VAST’s archive economics make it affordable to consolidate scratch and nearline tiers to a single flash tier. When all data is available for processing at NVMe speed researchers no longer need to stage or curate data sets and AI-powered workloads benefit from uncompromised random IO performance. Further simplifying data management, VAST automatically indexes file and object metadata to the built-in and always-in-sync VAST Catalog. Researchers can search and find data faster and administrators can analyze application behavior and audit access with an intuitive UI and SQL interface for advanced queries.


The main strategy is to have traverse storage on our system in order to be able to optimize all the movement. To have a single layer of access between different data centers to provide security on this particular storage in order to allow all of the workflows that we can think of in our complex environment. Today with the technology that we have today it is not possible. We are solving this with VAST.
When teams spend less effort tuning and troubleshooting, when scheduled downtime and outages are eliminated, researchers get more time to run simulations and analyze data. With all-flash performance that is orders of magnitude faster than spinning disk, computational jobs finish faster, reducing power consumption to make HPC data centers more sustainable. And when researchers need 1000s of cores for complex simulations VAST’s global namespace that unifies cloud, edge, and core makes it simple to burst to the cloud. The VAST Data Platform is unified and built as a singular intelligent system that increases the productivity of HPC and AI-powered research and helps customers drive value from their supercomputing investments.
Deploy all-flash infrastructure for all data sets. VAST’s new advancements in commodity flash management, data protection and reduction deliver a lower TCO than hybrid storage alternatives.
Eliminate the need for tiering appliances, client agents, data migrations, and other complications with a single, simple-to-manage, enterprise solution.
A unified multi-protocol platform for both unstructured (NFS, SMB, and S3) and structured data with support for native SQL applications and query engines such as Spark and Trino.
With support for NFS-over-RDMA and NVIDIA Magnum IO GPUDirect™ Storage access, VAST delivers the performance of a parallel file system without any of the parallel file system complexity.
Defeat data gravity with granular policy driven data access from anywhere in the VAST DataSpace.
With always online upgrades and expansions and no complex tuning required research teams gain insights faster.
Learn how to eliminate the operational complexity associated with legacy parallel file systems and deliver unprecedented simplicity and scale for highly demanding workloads.
LLNL selected VAST’s high-performance & easy to use all-flash based VAST Data Platform to unleash their HPC and Machine Learning efforts to drive drug efficacy.