
Did someone say ‘hype’? Artificial Intelligence (AI) represents what may be the single biggest opportunity to accelerate the evolution of humanity – with the potential to change how societies operate, how industries produce and how humans interact with the world. But… wow … the hype. The AI race is on... and every technology company is racing to establish themselves as the undisputed leader in this nascent race to define what artificial intelligence actually is and how it can impact our lives… where marketing dollars can even overshadow R&D investment.
You gotta love free markets. We now have some famous examples of the reality of current AI initiatives being way behind their marketing claims: ranging from the challenges associated with the Watson project to how self-driving cars may be much farther out than any of us hope. These lessons tell us that while there’s so much promise in AI, there’s still also a ton of hype, and they serve as a cautionary tale to look beyond the marketing to understand the reality.
The data storage market is no less immune to this hype cycle. Here you also find the intersection of hype and AI driven by marketing dollars. Storage vendors are crazy for AI for a variety of reasons:
AI is a new application, so it’s net-new business where there’s no established incumbent
AI is a killer use case for flash – Nvidia has explained to us that the average file request size is between 64KB and 1MB for deep learning workflows. At 64KB, it would require approximately 5,000!! HDDs to deliver the random read IOPS needed to saturate (for example) an NVIDIA DGX server at 20GB/s because HDDs are not well equipped for random read workloads. Flash is the answer for random ML/DL reads because NVMe Flash drives can deliver up to 1000x the performance of HDDs for this workload.
The capacities are big… where projects can require dozens to 100s of petabytes
Enter the hype. In AI storage … you see two camps emerge, each with their pros and cons:
| ALL-FLASH NAS APPLIANCES | FLASH-BASED HPC FILE SYSTEMS |
single mount GB/s | 2GB/s (TCP-limited) | 10GB/s+ (RDMA-enabled) |
connectivity | TCP Ethernet | Infiniband, RoCE Ethernet |
simplicity | simple appliances, no clients | complex integration projects |
scale | PBs | 100s of PBs |
cost | $$$ | $$ |
Challenges with All-Flash NAS Appliances for AI
In camp #1, you have the legacy NAS appliance vendors who claim to take the guesswork out of AI by packaging up ‘reference architectures’ that serve as deployment blueprints to promote their flash appliances for deep learning and machine learning use cases. As outlined above, simplicity comes at a significant cost.
Performance: Probably the #1 challenge with traditional NAS systems is that the performance that these file servers deliver is insufficient for the needs of a modern GPU server. GPU machines today are outfitted with 100s of Gbps of connectivity and in order to keep the GPUs efficiently training and inferring on large AI data sets, data must be moved into these machines at rates well beyond what classic TCP-based NAS is capable of delivering. By under-serving single-mount performance,customers face the prospect of wasting valuable GPU time while NAS systems struggle to feed training and inference models. Nvidia DGX systems have multiple ports of 100Gb Ethernet or InfiniBand.TCP-based NAS systems can only stream data into these systems at a rate of 16Gbps per client mount point. Even with multiple mount points, legacy NAS systems are unable to saturate the total capability of a GPU machine
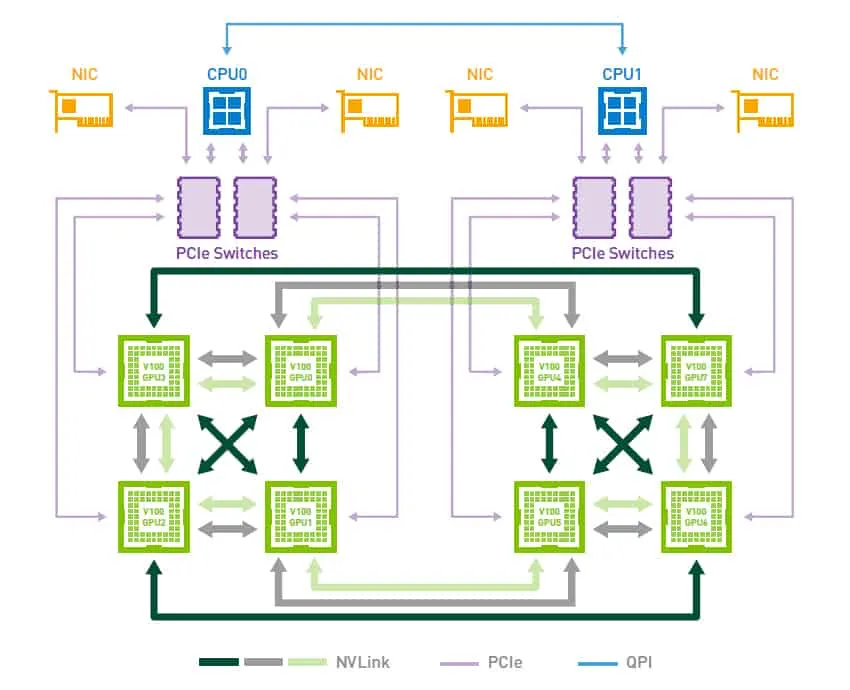
Interconnects: While distributed AI frameworks can be built on either InfiniBand or Ethernet networking, NAS appliances can be limiting since they lack support for InfiniBand connectivity.
Scale: Most NAS appliances were not designed for exabyte scale, and can today only be scaled to a few PBs in a single namespace that can be accessed
Cost: Enterprise All-Flash NAS systems can ‘break the bank’ for large AI projects because they were never designed to optimize the cost of infrastructure such that they can never rival the cost of an archive.

Challenges with HPC File Systems for AI
In camp #2, you have the HPC file systems that optimize performance by housing data in a ‘burst’ tier of Flash to optimize for performance while also enabling long-tail AI data to be tiered off to lower-cost HDD-based storage. These systems are often the product of a SW-based file system layered onto some third-party storage HW and can accelerate client-side access with the use of a custom, RDMA file system driver. Speed, however, is not an absolute when dealing with tiered infrastructure – and the complexity of deployment is dramatically greater as compared to NAS appliances.
Performance: HPC file system performance is great when data is serviced off of Flash. Once read requests must be read from some subordinate tier of HDDs, performance goes through the floor. A picture says a thousand words:

Whereas it’s easy to deterministically write data into a ‘burst buffer’ flash file system, the read problem is intrinsically more complex to deal with as many workloads are not declarative about their intent to read a piece of data until they actually need it. File systems can be smart about pre-fetching data when dealing with GBs of data… but, it’s nearly impossible to pre-fetch a random read in AI workflows because the read requests are small and in the KBs range. When a facial recognition model is retrained, the system reads all the relevant photos in the training corpus without creating the kind of repeated I/O hot-spots that storage caches have been designed to optimize for. It’s like pulling a tractor trailer with a formula 1 car… For this reason, we’ve seen GPU performance fall off a cliff when dealing with ‘cache misses’, when a client can step down from 10GB/s of streaming performance to just 200MB/s of streaming performance… a performance loss of 50x.
Complexity: with HPC file systems, complexity takes many forms:
Client-Side Complexity: By integrating a client-side driver into GPU servers, HPC file systems create an additional layer of dependencies when dealing with both file system and operating system upgrades. Infrastructure updates need to be more carefully planned because of the storage’s integration with the GPU server’s OS.
Storage integration challenges: Parallel file systems have the advantage of being deployed on any choice of hardware – but this freedom can turn nearly every deployment into an integration challenge. Some systems tier their data to third-party archive systems, this can introduce 1-2 additional integration complexities. Of course, all of this comes to a head when working through support issues where a bouillabaisse of storage vendors can all point fingers at each other.
Cost: HPC File Systems were not designed to combine the performance of Flash with the economics of an archive – as such, customers seek out ways to reduce costs through storage tiering… while this may save on storage costs, it increases the overall cost of GPU computing as GPU systems become far less efficient.

The Solution: VAST Data with Enhanced NFS Support for RDMA

VAST Data’s north star has always been to break the tradeoffs between performance and capacity by engineering a new VAST Data Platform that combines all-flash performance with archive economics. We’ve now applied this concept to make AI pipelines work faster even in the face of rapidly changing application requirements.
Our exabyte-scale architecture now features RDMA server extensions to the NFS protocol as to enable our scale-out file servers to feed AI infrastructure at line speed. There’s no proprietary file system client driver… everything is already in stock linux kernels. Beyond simplicity, the result is speed:
| single mount point per GPU server | multiple mount points per GPU server |
NFSoTCP | 2.1 GB/s | 8 GB/s |
NFSoRDMA | 8.7 GB/s | 20.5 GB/s |
VAST has redefined flash capacity affordability to eliminate the economic motivations that have lead to data tiering and complexity. By consolidating all of an AI corpus on Flash… our client performance is always fast and never suffers the pitfalls of storage tiering. GPU servers then become ultimately more productive and our customers can get their code and their AI-infused products to market quicker than ever.
| all-flash NAS appliances | flash-based HPC file systems | VAST |
single mount GB/s | 2GB/s (TCP-limited) | 10GB/s+ (RDMA-enabled) | 8.7GB/s+ RDMA |
connectivity | TCP Ethernet | Infiniband, RoCE Ethernet | Infiniband, RoCE Ethernet |
simplicity | simple appliances, no clients | complex integration projects | simple appliances |
scale | PBs | 100s of PBs | exabyte-scale |
cost | $$$ | $$ | revolutionary economics |
The hype machine continues on for many storage vendors talking about performance — yet their simplicity is not always so clear. A lot of the reason is, no one wants to talk about cost. If you can solve all three, it is the trifecta the market has been waiting for. No storage vendor has yet tackled the problem from all dimensions. That's why we're so excited about the possibilities of the VAST Data Platform for these modern workloads.


